Designing Data Intensive Applications - Chapter 10
Book Summary

Introduction
- Response time of a request is usually the primary measure of performance of a service, and availability is often very important.
Stream processing is somewhere between online and offline/batch processing so it is sometimes called near-real-time or nearline processing.
MapReduce is a fairly low-level programming model compared to the parallel processing systems that were developed for data warehouses many years previously, but it was a major step forward in terms of the scale of processing that could be achieved on commodity hardware.
Batch Processing with Unix Tools
Simple Log Analysis
- The sort utility in GNU Coreutils (Linux) automatically handles larger-than memory datasets by spilling to disk, and automatically parallelizes sorting across multiple CPU cores. The bottleneck is likely to be the rate at which the input file can be read from disk.
The Unix Philosophy
- The idea of connecting programs with pipes became part of what is now known as the "Unix philosophy".
Unix Philosophy Principles
Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”.
Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input.
Design and build software, even operating systems, to be tried early, ideally within weeks. Don’t hesitate to throw away the clumsy parts and rebuild them.
Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the tools and expect to throw some of them out after you’ve finished using them.
Not many pieces of software interoperate and compose as well as Unix tools can do.
The biggest limitation of Unix tools is that they run only on a single machine, and that’s where tools like Hadoop come in.
MapReduce and Distributed Filesystems
MapReduce is a bit like Unix tools, but distributed across potentially thousands of machines. Like Unix tools, it is a fairly blunt, brute-force, but surprisingly effective tool.
While Unix tools use stdin and stdout as input and output, MapReduce jobs read and write files on a distributed filesystem.
Various other distributed filesystems besides HDFS exist, such as GlusterFS and the Quantcast File System (QFS).
HDFS is based on the shared-nothing principle.
- HDFS consists of a daemon process running on each machine, exposing a network service that allows other nodes to access files stored on that machine.
MapReduce Job Execution
MapReduce is a programming framework with which you can write code to process large datasets in a distributed filesystem like HDFS.
The mapper is called once for every input record, and its job is to extract the key and value from the input record. For each input, it may generate any number of key-value pairs (including none).
The MapReduce framework takes the key-value pairs produced by the mappers, collects all the values belonging to the same key, and calls the reducer with an iterator over that collection of values.
The main difference from pipelines of Unix commands is that MapReduce can parallelize a computation across many machines, without you having to write code to explicitly handle the parallelism.
It is possible to use standard Unix tools as mappers and reducers in a distributed computation.
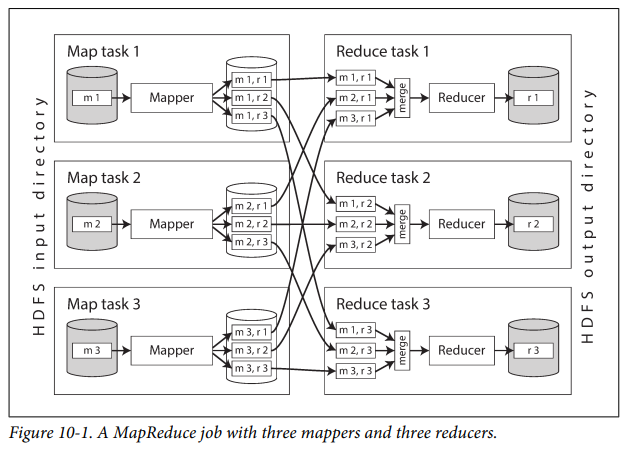
The reduce task takes the files from the mappers and merges them together, preserving the sort order.
It is very common for MapReduce jobs to be chained together into workflows, such that the output of one job becomes the input to the next job.
Various higher-level tools for Hadoop, such as Pig, Hive, Cascading, Crunch, and FlumeJava, also set up workflows of multiple MapReduce stages that are automatically wired together appropriately.
Reduce-Side Joins and Grouping
When a MapReduce job is given a set of files as input, it reads the entire content of all of those files; a database would call this operation a full table scan.
When we talk about joins in the context of batch processing, we mean resolving all occurrences of some association within a dataset.
In order to achieve good throughput in a batch process, the computation must be (as much as possible) local to one machine. Making random-access requests over the network for every record you want to process is too slow.
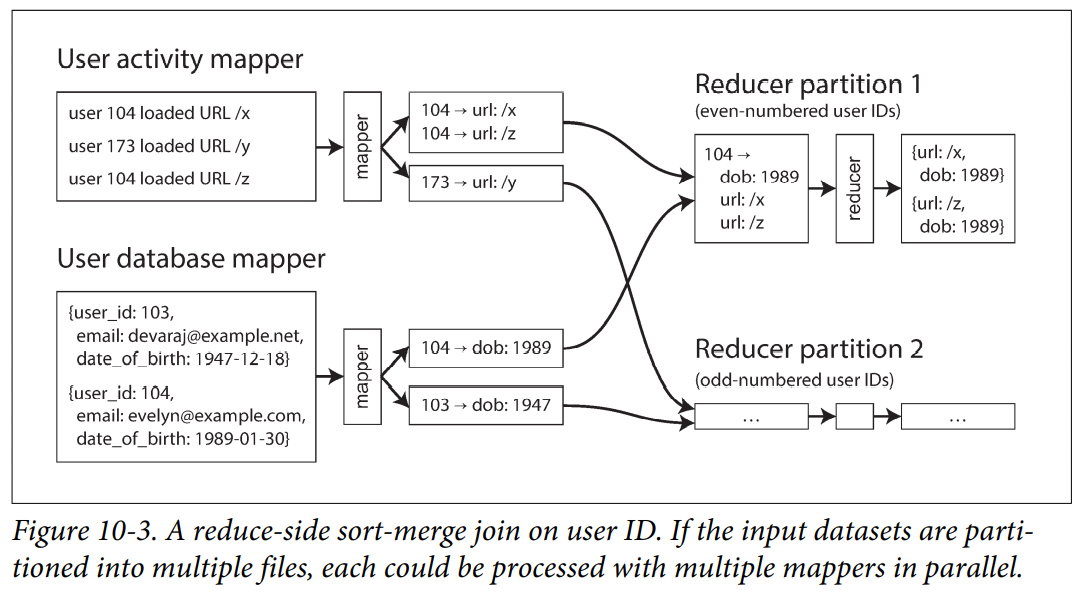
In a sort-merge join, the mappers and the sorting process make sure that all the necessary data to perform the join operation for a particular user ID is brought together in the same place.
Using the MapReduce programming model has separated the physical network communication aspects of the computation from the application logic.
A common use for grouping is collating all the activity events for a particular user session, in order to find out the sequence of actions that the user took which is a process called sessionization.
The pattern of “bringing all records with the same key to the same place” breaks down if there is a very large amount of data related to a single key.
When grouping records by a hotkey and aggregating them, you can perform the grouping in two stages. The first MapReduce stage sends records to a random reducer, so that each reducer performs the grouping on a subset of records for the hotkey and outputs a more compact aggregated value per key. The second Map‐ Reduce job then combines the values from all of the first-stage reducers into a single value per key.
Map-Side Joins
The reduce-side approach has the advantage that you do not need to make any assumptions about the input data.
On the other hand, if you can make certain assumptions about your input data, it is possible to make joins faster by using a so-called "map-side join".
The simplest way of performing a map-side join applies in the case where a large dataset is joined with a small dataset.
If the inputs to the map-side join are partitioned in the same way, then the hash join approach can be applied to each partition independently.
If the partitioning is done correctly, you can be sure that all the records you might want to join are located in the same numbered partition.
Partitioned hash joins are known as "bucketed map joins" in Hive.
Map-side joins also make more assumptions about the size, sorting, and partitioning of their input datasets. Knowing about the physical layout of datasets in the distributed filesystem becomes important when optimizing join strategies.
The Output of Batch Workflows
Google’s original use of MapReduce was to build indexes for its search engine, which was implemented as a workflow of 5 to 10 MapReduce jobs.
If you need to perform a full-text search over a fixed set of documents, then a batch process is a very effective way of building the indexes.
Search indexes are just one example of the possible outputs of a batch processing workflow. Another common use for batch processing is to build machine learning systems such as classifiers and recommendation systems.
The Unix philosophy encourages experimentation by being very explicit about dataflow.
- The design principles that worked well for Unix also seem to be working well for Hadoop, but Unix and Hadoop also differ in some ways. For example, because most Unix tools assume untyped text files, they have to do a lot of input parsing. On Hadoop, some of those low-value syntactic conversions are eliminated by using more structured file formats: Avro and Parquet are often used, as they provide efficient schema-based encoding and allow the evolution of their schemas over time.
Comparing Hadoop to Distributed Databases
MPP databases focus on parallel execution of analytic SQL queries on a cluster of machines, while the combination of MapReduce and a distributed filesystem provides something much more like a general-purpose operating system that can run arbitrary programs.
Hadoop opened up the possibility of indiscriminately dumping data into HDFS, and only later figuring out how to process it further. By contrast, MPP databases typically require careful up-front modelling of the data and query patterns before importing the data into the database’s proprietary storage format.
Indiscriminate data dumping shifts the burden of interpreting the data.
Hadoop has often been used for implementing ETL processes.
MPP databases are monolithic, tightly integrated pieces of software that take care of storage layout on disk, query planning, scheduling, and execution.
In the Hadoop approach, there is no need to import the data into several different specialized systems for different kinds of processing.
The Hadoop ecosystem includes both random-access OLTP databases such as HBase and MPP-style analytic databases such as Impala.
When comparing MapReduce to MPP databases, two more differences in the design approach stand out: the handling of faults and the use of memory and disk.
MapReduce can tolerate the failure of a map or reduce task without it affecting the job as a whole by retrying work at the granularity of an individual task.
MapReduce is designed to tolerate frequent unexpected task termination.
Beyond MapReduce
Various higher-level programming models (Pig, Hive, Cascading, Crunch) were created as abstractions on top of MapReduce.
MapReduce is very robust: you can use it to process almost arbitrarily large quantities of data on an unreliable multi-tenant system with frequent task terminations, and it will still get the job done.
Materialization of Intermediate State
MapReduce job is independent from every other job.
The process of writing out this intermediate state to files is called "materialization".
MapReduce’s approach of fully materializing intermediate state downsides compared to Unix pipes
• A MapReduce job can only start when all tasks in the preceding jobs have been completed, whereas processes connected by a Unix pipe are started at the same time, with the output being consumed as soon as it is produced.
• Storing intermediate state in a distributed filesystem means those files are replicated across several nodes, which is often overkill for such temporary data.
- An advantage of fully materializing intermediate state to a distributed filesystem is that it is durable, which makes fault tolerance fairly easy in MapReduce.
- Recovering from faults by recomputing data is not always the right answer: if the intermediate data is much smaller than the source data, or if the computation is very CPU-intensive, it is probably cheaper to materialize the intermediate data to files than to recompute it.
Graphs and Iterative Processing
Dataflow engines like Spark, Flink, and Tez typically arrange the operators in a job as a directed acyclic graph (DAG).
It is possible to store a graph in a distributed filesystem (in files containing lists of vertices and edges), but this idea of “repeating until done” cannot be expressed in plain MapReduce.
The fact that vertices can only communicate by message passing (not by querying each other directly) helps improve the performance of Pregel jobs.
Pregel implementations guarantee that messages are processed exactly once at their destination vertex in the following iteration.
- Graph algorithms often have a lot of cross-machine communication overhead, and the intermediate state (messages sent between nodes) is often bigger than the original graph. The overhead of sending messages over the network can significantly slow down distributed graph algorithms.
High-Level APIs and Languages
Higher-level languages and APIs such as Hive, Pig, Cascading, and Crunch became popular because programming MapReduce jobs by hand is quite laborious.
An advantage of specifying joins as relational operators, compared to spelling out the code that performs the join, is that the framework can analyze the properties of the join inputs and automatically decide which of the aforementioned join algorithms would be most suitable for the task at hand.
MapReduce and its dataflow successors are very different from the fully declarative query model of SQL. MapReduce was built around the idea of function callbacks.
Hive, Spark DataFrames, and Impala use vectorized execution.
Approximate search is also important for genome analysis algorithms, which need to find strings that are similar but not identical.
Batch processing engines are being used for distributed execution of algorithms from an increasingly wide range of domains. As batch processing systems gain built-in functionality and high-level declarative operators, and as MPP databases become more programmable and flexible, the two are beginning to look more alike: in the end, they are all just systems for storing and processing data.
The distinguishing feature of a batch processing job is that it reads some input data and produces some output data, without modifying the input.
Thank you, and goodbye!




