Designing Data Intensive Applications - Chapter 11
Book Summary

The problem with daily batch processes is that changes in the input are only reflected in the output a day later, which is too slow for many impatient users.
“stream” refers to data that is incrementally made available over time.
Transmitting Event Streams
- In batch processing, a file is written once and then potentially read by multiple jobs. In streaming terminology, an event is generated once by a producer (sender), and then potentially processed by multiple consumers (recipients).
Messaging Systems
- A common approach for notifying consumers about new events is to use a messaging system.
If you can afford to sometimes lose messages, you can probably get higher throughput and lower latency on the same hardware.
A number of messaging systems use direct network communication between producers and consumers without going via intermediary nodes.
Direct messaging systems work well in the situations for which they are designed, they generally require the application code to be aware of the possibility of message loss.
Message broker is essentially a kind of database that is optimized for handling message streams [13]. It runs as a server, with producers and consumers connecting to it as clients.
Some message brokers only keep messages in memory, while others (depending on configuration) write them to disk so that they are not lost in case of a broker crash.
Message brokers VS Databases
Databases usually keep data until it is explicitly deleted, whereas most message brokers automatically delete a message when it has been successfully delivered to its consumers.
Databases often support secondary indexes and various ways of searching for data, while message brokers often support some way of subscribing to a subset of topics matching some pattern.
- Message brokers do not support arbitrary queries unlike the databases
- In order to ensure that the message is not lost, message brokers use acknowledgments: a client must explicitly tell the broker when it has finished processing a message so that the broker can remove it from the queue.
Partitioned Logs
Everything that is written to a database or file is normally expected to be permanently recorded, at least until someone explicitly chooses to delete it again.
The idea behind log-based message brokers is combining the durable storage approach of databases with the low-latency notification facilities of messaging.
A log is simply an append-only sequence of records on disk.
In order to scale to higher throughput than a single disk can offer, the log can be partitioned.
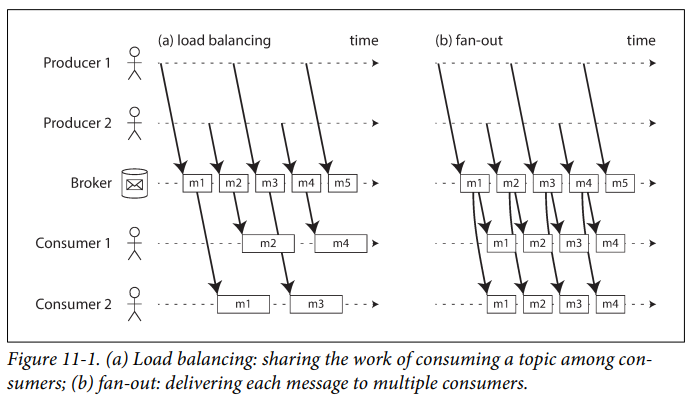
The log-based approach trivially supports fan-out messaging, because several consumers can independently read the log without affecting each other, reading a message does not delete it from the log.
in situations with high message throughput, where each message is fast to process and where message ordering is important, the log-based approach works very well.
Consuming a partition sequentially makes it easy to tell which messages have been processed.
If you only ever append to the log, you will eventually run out of disk space. To reclaim disk space, the log is actually divided into segments, and from time to time old segments are deleted or moved to archive storage.
If a consumer falls so far behind that the messages it requires are older than what is retained on disk, the broker effectively drops old messages that go back further than the size of the buffer can accommodate.
In a log-based message broker, consuming messages is more like reading from a file: it is a read-only operation that does not change the log.
Databases and Streams
- A replication log is a stream of database write events, produced by the leader as it processes transactions.
Keeping Systems in Sync
- If periodic full database dumps are too slow, an alternative that is sometimes used is "dual writes".
Dual writes have some serious problems, such as a "race condition", and one of the writes may fail while the other succeeds.
If you only have one replicated database with a single leader, then that leader determines the order of writes.
Change Data Capture
- CDC is the process of observing all data changes written to a database and extracting them in a form in which they can be replicated to other systems.
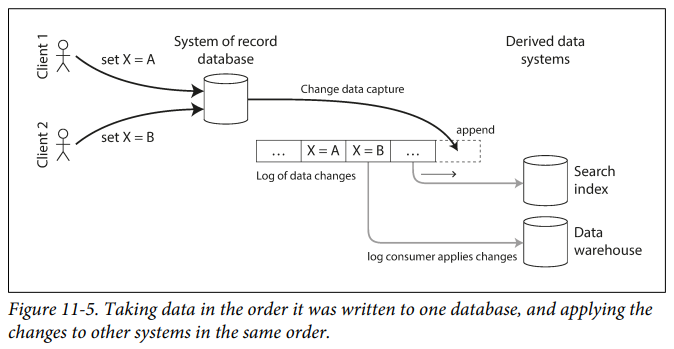
If you have the log of all changes that were ever made to a database, you can reconstruct the entire state of the database by replaying the log.
The snapshot of the database must correspond to a known position or offset in the change log.
In a log-structured storage engine, an update with a special null value (a tombstone) indicates that a key was deleted, and causes it to be removed during log compaction.
If the CDC system is set up such that every change has a primary key, and every update for a key replaces the previous value for that key, then it’s sufficient to keep just the most recent write for a particular key.
Kafka Connect is an effort to integrate change data capture tools for a wide range of database systems with Kafka.
Event Sourcing
Event sourcing is a powerful technique for data modelling.
Similarly to change data capture, event sourcing involves storing all changes to the application state as a log of change events. The biggest difference is that event sourcing applies the idea at a different level of abstraction.
Event sourcing is similar to the chronicle data model, and there are also similarities between an event log and the fact table that you find in a star schema.
A CDC event for the update of a record typically contains the entire new version of the record, so the current value for a primary key is entirely determined by the most recent event for that primary key, and log compaction can discard previous events for the same key.
The event sourcing philosophy is careful to distinguish between events and commands.
- A consumer of the event stream is not allowed to reject an event: by the time the consumer sees the event, it is already an immutable part of the log, and it may have already been seen by other consumers.
State, Streams, and Immutability
Whenever you have state that changes, that state is the result of the events that mutated it over time.
No matter how the state changes, there was always a sequence of events that caused those changes. Even as things are done and undone, the fact remains true that those events occurred.

Log compaction is one way of bridging the distinction between log and database state: it retains only the latest version of each record, and discards overwritten versions.
Immutable events capture more information than just the current state.
By separating mutable state from the immutable event log, you can derive several different read-oriented representations from the same log of events.
Having an explicit translation step from an event log to a database makes it easier to evolve your application over time.
The traditional approach to database and schema design is based on the fallacy that data must be written in the same form as it will be queried.
The biggest downside of event sourcing and change data capture is that the consumers of the event log are usually asynchronous, so there is a possibility that a user may make a write to the log, then read from a log-derived view and find that their write has not yet been reflected in the read view.
Many systems that don’t use an event-sourced model rely on immutability.
Truly deleting data is surprisingly hard, since copies can live in many places: for example, storage engines, filesystems, and SSDs often write to a new location rather than overwriting in place, and backups are often deliberately immutable to prevent accidental deletion or corruption.
Processing Streams
- The patterns for partitioning and parallelization in stream processors are also very similar to those in MapReduce and the dataflow engines.
Uses of Stream Processing
Stream processing has long been used for monitoring purposes, where an organization wants to be alerted if certain things happen.
Complex event processing (CEP) is an approach developed in the 1990s for analyzing event streams, especially geared toward the kind of application that requires searching for certain event patterns.
Usually, a database stores data persistently and treats queries as transient: when a query comes in, the database searches for data matching the query, and then forgets about the query when it has finished.
Stream analytics systems sometimes use probabilistic algorithms, such as Bloom filters for set membership, HyperLogLog for cardinality estimation, and various percentile estimation algorithms.
Any stream processor could be used for materialized view maintenance.
Searching a stream turns the processing on its head: the queries are stored, and the documents run past the queries, like in CEP. In the simplest case, you can test every document against every query, although this can get slow if you have a large number of queries.
Reasoning About Time
In a batch process, the processing tasks rapidly crunch through a large collection of historical events.
Many stream processing frameworks use the local system clock on the processing machine to determine windowing. This approach has the advantage of being simple, and it is reasonable if the delay between event creation and event processing is negligibly short.
Message delays can lead to unpredictable ordering of messages.
Confusing event time and processing time leads to bad data.
Assigning timestamps to events is even more difficult when events can be buffered at several points in the system.
The clock on a user-controlled device often cannot be trusted, as it may be accidentally or deliberately set to the wrong time.
Types of Windows That are Common
Tumbling window : it has a fixed length, and every event belongs to exactly one window.
Hopping window : it has a fixed length, but allows windows to overlap in order to provide some smoothing.
Sliding window : it contains all the events that occur within some interval of each other.
Session window : it has no fixed duration. It is defined by grouping together all events for the same user that occur closely together in time, and the window ends when the user has been inactive for some time.
Stream Joins
A stream-table join is actually very similar to a stream-stream join; the biggest difference is that for the table changelog stream, the join uses a window that reaches back to the “beginning of time”, with newer versions of records overwriting older ones. For the stream input, the join might not maintain a window at all.
In a partitioned log, the ordering of events within a single partition is preserved, but there is typically no ordering guarantee across different streams or partitions.
Fault Tolerance
Microbatching implicitly provides a tumbling window equal to the batch size (windowed by processing time, not event timestamps); any jobs that require larger windows need to explicitly carry over state from one microbatch to the next.
Our goal is to discard the partial output of any failed tasks so that they can be safely retried without taking effect twice. Distributed transactions are one way of achieving that goal, but another way is to rely on idempotence.
If an operation is not naturally idempotent, it can often be made idempotent with a bit of extra metadata.
Any stream process that requires state, for example, any windowed aggregations (such as counters, averages, and histograms) and any tables and indexes used for joins must ensure that this state can be recovered after a failure.
One option is to keep the state in a remote datastore and replicate it, although having to query a remote database for each individual message can be slow.
In some systems, network delay may be lower than disk access latency, and network bandwidth may be comparable to disk bandwidth. There is no universally ideal trade-off for all situations, and the merits of local versus remote state may also shift as storage and networking technologies evolve.
Thank you, and goodbye!




