Designing Data Intensive Applications - Chapter 2
Book Summary

Relational Model Versus Document Model
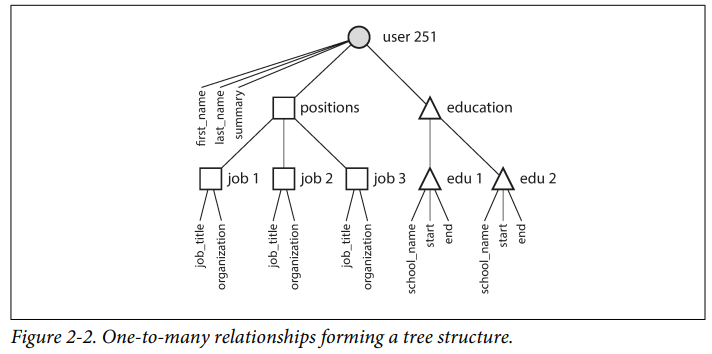
- Historically, data started out being represented as one big tree (the hierarchical model), but that wasn’t good for representing many-to-many relationships, so the relational model was invented to solve that problem.
The Birth of NoSQL
The name “NoSQL” was originally intended simply as a catchy Twitter hashtag for a meetup on open source, distributed, nonrelational databases in 2009. A number of interesting database systems are now associated with the #NoSQL hashtag, and it has been retroactively reinterpreted as Not Only SQL.
The driving forces behind the adoption of NoSQL databases :
• A need for greater scalability than relational databases can easily achieve, including very large datasets or very high write throughput.
• A widespread preference for free and open source software over commercial database products.
• Specialized query operations that are not well supported by the relational model.
• Frustration with the restrictiveness of relational schemas, and a desire for a more dynamic and expressive data model.
The Object-Relational Mismatch
Most application development today is done in object-oriented programming languages, which leads to a common criticism of the SQL data model: if data is stored in relational tables, an awkward translation layer is required between the objects in the application code and the database model of tables, rows, and columns.
The disconnect between the models is sometimes called an impedance mismatch. Object-relational mapping (ORM) frameworks like ActiveRecord and Hibernate reduce the amount of boilerplate code required for this translation layer, but they can’t completely hide the differences between the two models.
For a data structure like a résumé, which is mostly a self-contained document, a JSON representation can be quite appropriate. JSON has the appeal of being much simpler than XML.
The JSON representation has better locality than the multi-table schema.
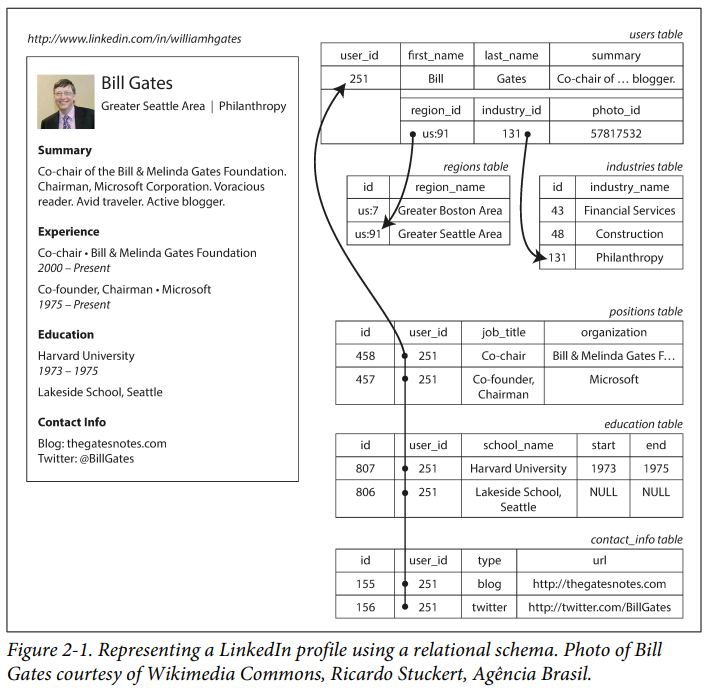
Many-to-One and Many-to-Many Relationships
- The advantage of using an
IDis that because it has no meaning to humans, it never needs to change: theIDcan remain the same, even if the information it identifies changes.
In document databases, joins are not needed for one-to-many tree structures, and support for joins is often weak.
Even if the initial version of an application fits well in a join-free document model, data has a tendency of becoming more interconnected as features are added to applications.
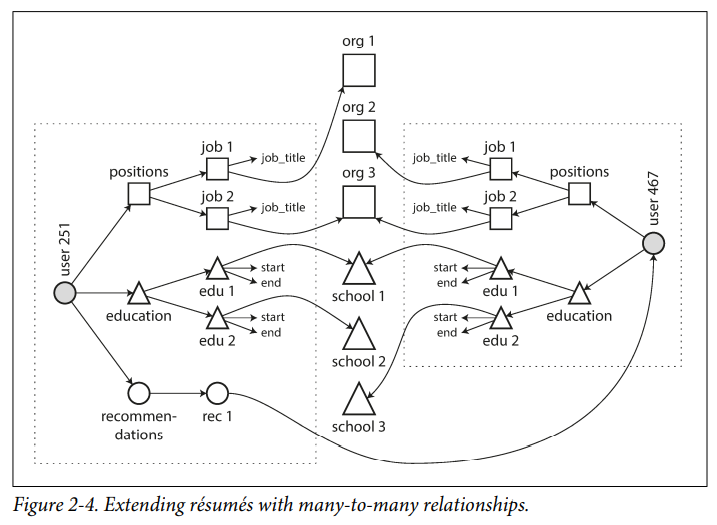
Are Document Databases Repeating History?
Various solutions were proposed to solve the limitations of the hierarchical model.
The two most prominent were :
- The relational model (which became SQL, and took over the world).
The network model (which initially had a large following but eventually faded into obscurity).
The network model (CODASYL) model was a generalization of the hierarchical model. In the tree structure of the hierarchical model, every record has exactly one parent; in the network model, a record could have multiple parents.
The links between records in the network model were not foreign keys, but more like pointers in a programming language (while still being stored on disk). The only way of accessing a record was to follow a path from a root record along these chains of links. This was called an access path. In the simplest case, an access path could be like the traversal of a linked list.
In a relational database, the query optimizer automatically decides which parts of the query to execute in which order, and which indexes to use. Those choices are effectively the “access path,” but the big difference is that they are made automatically by the query optimizer, not by the application developer, so we rarely need to think about them.
Relational Versus Document Databases Today
The main arguments in favour of the document data model are schema flexibility, better performance due to the locality, and that for some applications it is closer to the data structures used by the application.
The relational model counters by providing better support for joins, and many-to-one and many-to-many relationships.
The document model has limitations: for example, you cannot refer directly to a nested item within a document.
If your application does use many-to-many relationships, the document model becomes less appealing. It’s possible to reduce the need for joins by denormalizing, but then the application code needs to do additional work to keep the denormalized data consistent.
No schema means that arbitrary keys and values can be added to a document, and when reading, clients have no guarantees as to what fields the documents may contain.
schema-on-read (the structure of the data is implicit, and only interpreted when the data is read), in contrast with schema-on-write (the traditional approach of relational databases, where the schema is explicit and the database ensures all written data conforms to it).
Schema changes have a bad reputation of being slow and requiring downtime. Running the
UPDATEstatement on a large table is likely to be slow on any database since every row needs to be rewritten.
Advantages of schema-on-read approach :
There are many different types of objects, and it is not practical to put each type of object in its own table.
The structure of the data is determined by external systems over which you have no control and which may change at any time.
Query Languages for Data
An imperative language tells the computer to perform certain operations in a certain order.
function getSharks() { var sharks = []; for (var i = 0; i < animals.length; i++) { if (animals[i].family === "Sharks") { sharks.push(animals[i]); } } return sharks; }In a declarative query language, like SQL or relational algebra, you just specify the pattern of the data you want (what conditions the results must meet, and how you want the data to be transformed) but not how to achieve that goal.
SELECT * FROM animals WHERE family = 'Sharks';
Declarative Queries on the Web
- In a web browser, using declarative CSS styling is much better than manipulating styles imperatively in JavaScript. Similarly, in databases, declarative query languages like SQL turned out to be much better than imperative query APIs.
MapReduce Querying
MapReduce is a programming model for processing large amounts of data in bulk across many machines. It is neither a declarative query language nor a fully imperative query API, but somewhere in between. It doesn’t have a monopoly on distributed query execution.
The
mapandreducefunctions are somewhat restricted in what they are allowed to do. They must be pure functions, which means they only use the data that is passed to them as input, they cannot perform additional database queries, and they must not have any side effects.
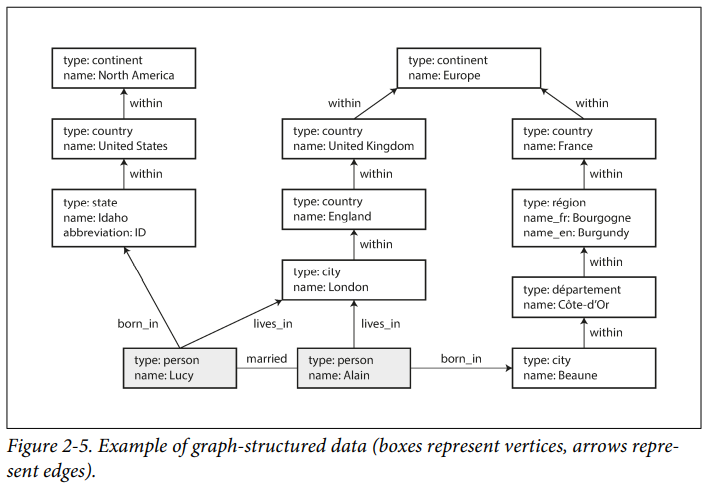
Graph-Like Data Models
Graph consists of two kinds of objects:
vertices(also known as nodes or entities) andedges(also known as relationships or arcs). Many kinds of data can be modelled as a graph. Such as Social graphs where Vertices are people, and edges indicate which people know each other.Graphs are not limited to such homogeneous data: an equally powerful use of graphs is to provide a consistent way of storing completely different types of objects in a single data store.
Property Graphs
- Each vertex consists of :
- A unique identifier.
- A set of outgoing edges.
- A set of incoming edges.
- A collection of properties (key-value pairs).
- Each edge consists of :
- A unique identifier.
- The vertex at which the edge starts (the tail vertex).
- The vertex at which the edge ends (the head vertex).
- A label to describe the kind of relationship between the two vertices.
A collection of properties (key-value pairs).
Any vertex can have an edge connecting it with any other vertex. There is no schema that restricts which kinds of things can or cannot be associated.
The Cypher Query Language
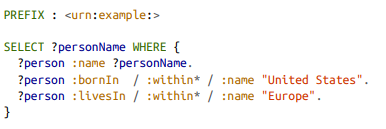
Cypheris a declarative query language for property graphs, created for theNeo4jgraph database.When all the vertices and edges are added to the database, to find the names of all the people who emigrated from the
United StatestoEurope. To be more precise, here we want to find all the vertices that have aBORN_INedge to a location within theUS, and also aLIVING_INedge to a location withinEurope, and return the name property of each of those vertices.

Graph Queries in SQL
In Cypher,
:WITHIN*0..expresses that fact very concisely: it means “follow a WITHIN edge, zero or more times.” It is like the*operator in a regular expression.If the same query can be written in 4 lines in one query language (Cypher) but requires 29 lines in another (SQL), that just shows that different data models are designed to satisfy different use cases. So It’s important to pick a data model that is suitable for your application.
Triple-Stores and SPARQL
- The triple-store model is mostly equivalent to the property graph model, using different words to describe the same ideas.
The subject of a triple is equivalent to a vertex in a graph.
The semantic web was overhyped in the early 2000s but so far hasn’t shown any sign of being realized in practice, which has made many people cynical about it. It has also suffered from a dizzying plethora of acronyms, overly complex standards proposals, and hubris.
SPARQL is a query language for triple-stores using the RDF data model. It is an acronym for SPARQL Protocol and RDF Query Language. It predates Cypher.
- All three models (document, relational, and graph) are widely used today, and each is good in its respective domain.
The Foundation: Datalog
- Datalog is a much older language than SPARQL or Cypher, having been studied extensively by academics in the 1980s.
- Datalog’s data model is similar to the triple-store model, generalized a bit. So Instead of writing a triple as (subject, predicate, object), we write it as a predicate (subject, object). Datalog is a subset of Prolog.
Thank you, and goodbye!




