Designing Data Intensive Applications - Chapter 3
Book Summary

Hash Indexes
- In order to efficiently find the value for a particular key in the database, we need a different data structure: an index.
- The general idea behind hash indexes is to keep some additional metadata on the side, which acts as a signpost and helps you to locate the data you want. If you want to search the same data in several different ways, you may need several different indexes on different parts of the data.
Well-chosen indexes speed up read queries, but every index slows down writes.
When our data storage consists only of appending to a file, the simplest possible indexing strategy is to keep an in-memory hash map where every key is mapped to a byte offset in the data file.
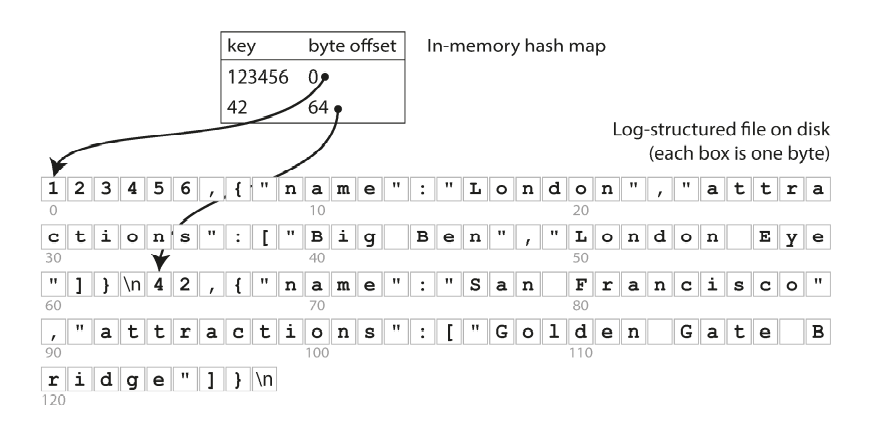
Bitcask storage engine is well suited to situations where the value for each key is updated frequently.
We will break the log into segments of a certain size by closing a segment file when it reaches a certain size, and making subsequent writes to a new segment file. We can then perform compaction on these segments. we can also merge several segments together at the same time as performing the compaction.
Compaction means throwing away duplicate keys in the log, and keeping only the most recent update for each key.

Problems of Append-only Approach
Deleting records : If you want to delete a key and its associated value, you have to append a special deletion record to the data file (sometimes called a tombstone).
Crash recovery : If the database is restarted, the in-memory hash maps are lost.
Partially written records : The database may crash at any time, including halfway through appending a record to the log.
- Concurrency control
Limitations of Hash Tables
- The hash table must fit in memory, so if you have a very large number of keys, you’re out of luck.
- Range queries are not efficient. For example, you cannot easily scan over all keys between
kitty00000andkitty99999you’d have to look up each key individually in the hash maps.
SSTables and LSM-Trees
- Sorted String Table, or SSTable for short stands for the format where we require that the sequence of key-value pairs is sorted by key.
SSTables Advantages Over Log Segments
- Merging segments is simple and efficient, even if the files are bigger than the available memory.
- In order to find a particular key in the file, you no longer need to keep an index of all the keys in memory.
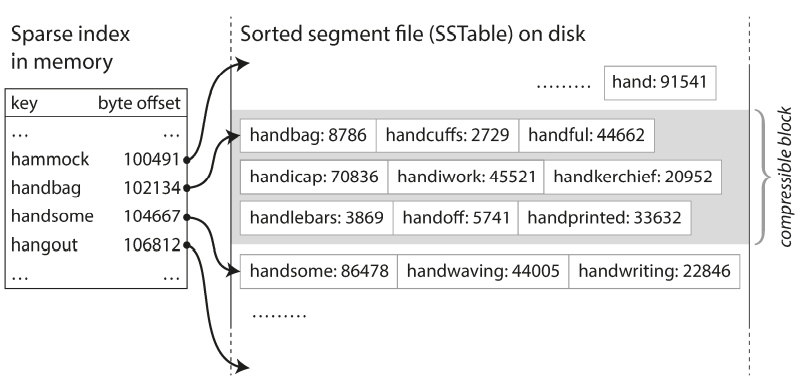
it is possible to group those records into a block and compress it before writing it to disk.
Maintaining a sorted structure on disk is possible, but maintaining it in memory is much easier.
The Way the Storage Engine Works
• When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.
• When the memtable gets bigger than some threshold—typically a few megabytes —write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.
• In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the next-older segment, etc.
• From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values. We can also keep a separate log on disk to which every write is immediately appended for the case if the database crashes, the most recent writes.
B-Trees
The most widely used indexing structure is quite different: the "B-tree".
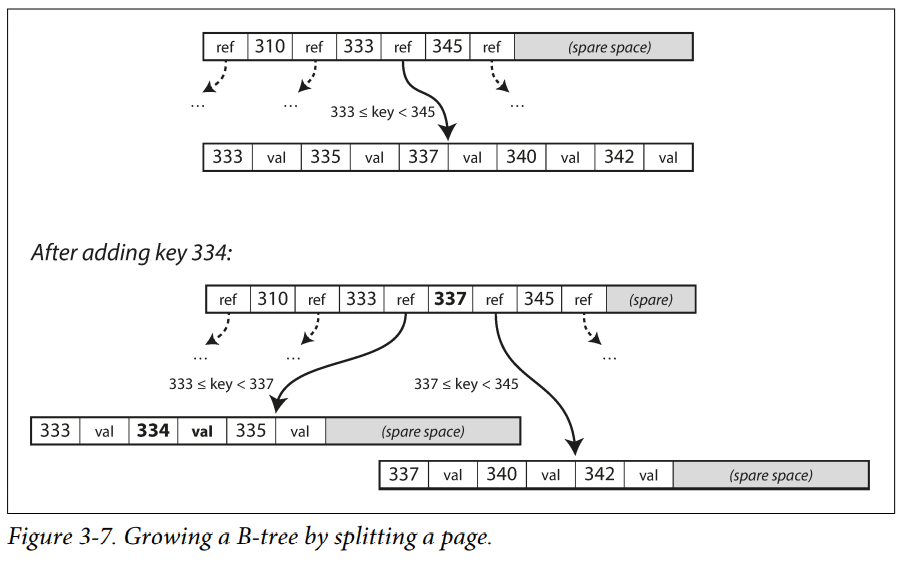
B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time, Each page can be identified using an address or location, which allows one page to refer to another (similar to a pointer but on disk instead of in memory). Each child is responsible for a continuous range of keys
Ways to Optimize B-trees
- A modified page is written to a different location, and a new version of the parent pages in the tree is created, pointing at the new location.
- We can save space in pages by not storing the entire key, but abbreviating it.
- Additional pointers have been added to the tree. For example, each leaf page may have references to its sibling pages to the left and right, which allows scanning keys in order without jumping back to parent pages.
- B-tree variants such as fractal trees borrow some log-structured ideas to reduce disk seeks.
Comparing B-Trees and LSM-Trees
Advantages of LSM-trees
- LSM-trees are typically able to sustain higher write throughput than B-trees, partly because they sometimes have lower write amplification (although this depends on the storage engine configuration and workload).
- LSM-trees can be compressed better, and thus often produce smaller files on disk than B-trees.
Downsides of LSM-trees
The compaction process can sometimes interfere with the performance of ongoing reads and writes.
the disk’s finite write bandwidth needs to be shared between the initial write (logging and flushing a memtable to disk) and the compaction threads running in the background.
If write throughput is high and compaction is not configured carefully, it can happen that compaction cannot keep up with the rate of incoming writes. In this case, the number of unmerged segments on disk keeps growing until you run out of disk space, and reads also slow down.
Log-structured storage engine may have multiple copies of the same key in different segments, unlike B-trees where each key exists in exactly one place in the index.
Other Indexing Structures
It is also very common to have secondary indexes. It can easily be constructed from a key-value index. The main difference is that keys are not unique so there might be many rows (documents, vertices) with the same key.
Both B-trees and log-structured indexes can be used as secondary indexes.
The place where rows are stored when get selected is known as a heap file, and it stores data in no particular order.
When updating a value without changing the key, the heap file approach can be quite efficient: the record can be overwritten in place, provided that the new value is not larger than the old value.
A compromise between a clustered index (storing all row data within the index) and a nonclustered index (storing only references to the data within the index) is known as a covering index or index with included columns, which stores some of a table’s columns within the index. This allows some queries to be answered by using the index alone.
Multi-column Indexes
- Multi-dimensional indexes are a more general way of querying several columns at once, which is particularly important for geospatial data. They are formed by multiple search keys.
Keeping Everything in Memory
As RAM becomes cheaper, the cost-per-gigabyte argument is eroded. Many datasets are simply not that big, so it’s quite feasible to keep them entirely in memory potentially distributed across several machines. This has led to the development of in-memory databases.
Counterintuitively, the performance advantage of in-memory databases is not due to the fact that they don’t need to read from disk. Rather, they can be faster because they can avoid the overheads of encoding in-memory data structures in a form that can be written to disk.
in-memory databases is providing data models that are difficult to implement with disk-based indexes.
Recent research indicates that an in-memory database architecture could be extended to support datasets larger than the available memory, without bringing back the over‐heads of a disk-centric architecture.
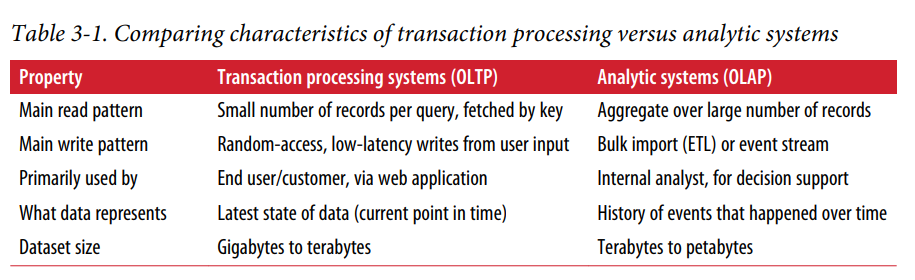
OLTP (Online Transaction Processing) is a type of data processing that consists of executing a number of transactions occurring concurrently online banking, shopping, order entry, or sending text.
OLAP (Online Analytical Processing) is software for performing multidimensional analysis at high speeds on large volumes of data from a data warehouse, data mart, or some other unified, centralized data store.
Storage Engines From Two Main Schools of Thought via OLTP:
- The log-structured school only permits appending to files and deleting obsolete files, but never updates a file that has been written. Bitcask, SSTables, LSM-trees, LevelDB, Cassandra, HBase, Lucene, and others belong to this group.
- The update-in-place school treats the disk as a set of fixed-size pages that can be overwritten. B-trees are the biggest example of this philosophy, being used in all major relational databases and also many nonrelational ones.
Data Warehousing
- A data warehouse, by contrast, is a separate database that analysts can query to their hearts’ content, without affecting OLTP operations. The data warehouse contains a read-only copy of the data in all the various OLTP systems in the company. Data is extracted from OLTP databases, transformed into an analysis-friendly schema, cleaned up, and then loaded into the data warehouse.
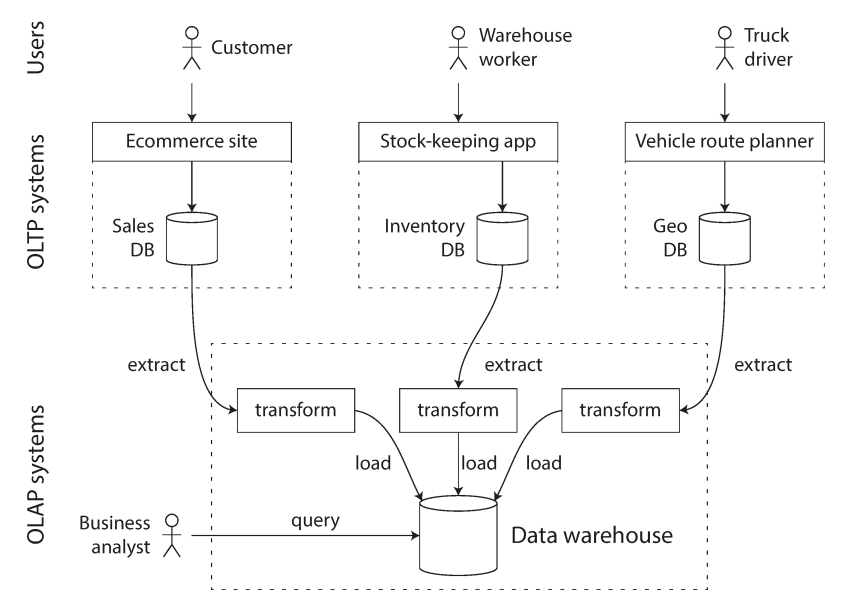
- An advantage of using a separate data warehouse, rather than querying OLTP systems directly for analytics, is that the data warehouse can be optimized for analytic access patterns.
Stars and Snowflakes: Schemas for Analytics
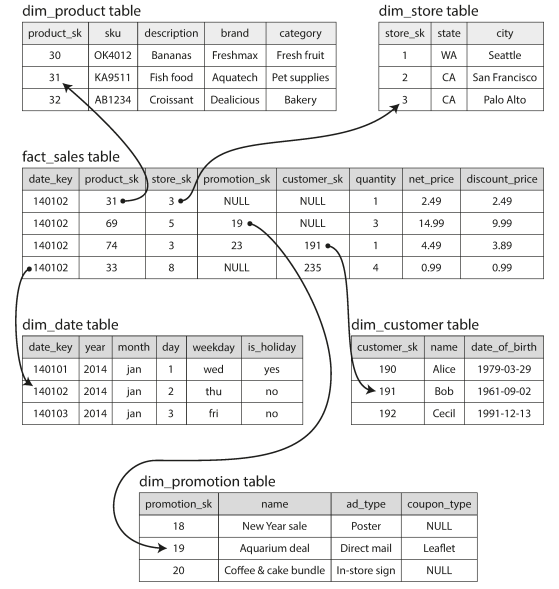
- In analytics, there is much less diversity of data models. Many data warehouses are used in a fairly formulaic style, known as a star schema (also known as dimensional modelling).
- Each row of the fact table represents an event that occurred at a particular time. ). Other columns in the fact table are foreign key references to other tables, called dimension tables
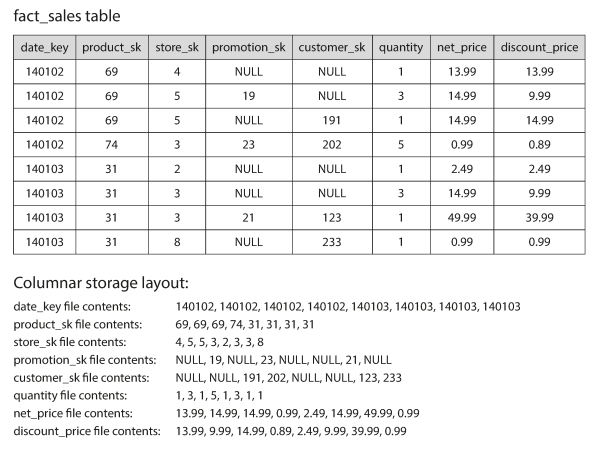
Column Compression
- The idea behind column-oriented storage is that we don’t store all the values from one row together, but store all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are used in that query, which can save a lot of work.
Sort Order in Column Storage
- If the data needs to be sorted an entire row at a time, even though it is stored by column. The administrator of the database can choose the columns by which the table should be sorted, using their knowledge of common queries. We can also apply compression of columns.
Writing to Column-Oriented Storage
- An update-in-place approach, like B-trees use, is not possible with compressed columns. If you wanted to insert a row in the middle of a sorted table, you would most likely have to rewrite all the column files. As rows are identified by their position within a column, the insertion has to update all columns consistently.
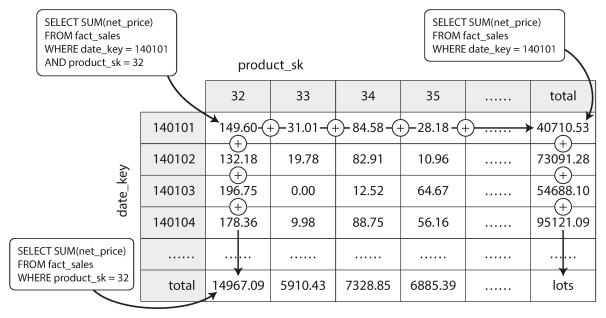
Aggregation: Data Cubes and Materialized Views
- Materialized view is an actual copy of the query results, written to disk, whereas a virtual view is just a shortcut for writing queries.
- Data cube or OLAP cube is a grid of aggregates grouped by different dimensions. As shown in the following photo :
Thank you, and goodbye!




