Designing Data Intensive Applications - Chapter 4
Book Summary

in a large application, code changes often cannot happen instantaneously:
- With server-side applications you may want to perform a rolling upgrade, deploying the new version to a few nodes at a time, checking whether the new version is running smoothly, and gradually working your way through all the nodes. This allows new versions to be deployed without service downtime, and thus encourages more frequent releases and better evolvability.
- With client-side applications you’re at the mercy of the user, who may not install the update for some time.
We need to maintain compatibility in both directions:
- Backward compatibility Newer code can read data that was written by older code.
- Forward compatibility Older code can read data that was written by newer code
Formats for Encoding Data
Programs usually work with data in (at least) two different representations:
In memory, data is kept in objects, structs, lists, arrays, hash tables, trees, and so on. These data structures are optimized for efficient access and manipulation by the CPU (typically using pointers).
When you want to write data to a file or send it over the network, you have to encode it as some kind of self-contained sequence of bytes (for example, a JSON document).
Language-Specific Formats
Problems of Encoding Libraries :
The encoding is often tied to a particular programming language, and reading the data in another language is very difficult.
In order to restore data in the same object types, the decoding process needs to be able to instantiate arbitrary classes and this is frequently a source of security problems.
Versioning data is often an afterthought in these libraries.
Efficiency (CPU time taken to encode or decode, and the size of the encoded structure) is also often an afterthought.
- it’s generally a bad idea to use your language’s built-in encoding for anything other than very transient purposes.
JSON, XML, and Binary Variants
JSON, XML, and CSV Problems
There is a lot of ambiguity around the encoding of numbers. In XML and CSV, you cannot distinguish between a number and a string that happens to consist of digits (except by referring to an external schema).
JSON and XML have good support for Unicode character strings (i.e., human-readable text), but they don’t support binary strings (sequences of bytes without a character encoding).
Many JSON-based tools don’t bother using schemas. And since the correct interpretation of data depends on the information in the schema, applications that don’t use XML/JSON schemas need to potentially hardcode the appropriate encoding/decoding logic instead.
CSV does not have any schema, so it is up to the application to define the meaning of each row and column.
Binary encodings for JSON includes MessagePack, BSON, BJSON, UBJSON, and BISON.
Binary encodings for XML includes WBXML and Fast Infoset.
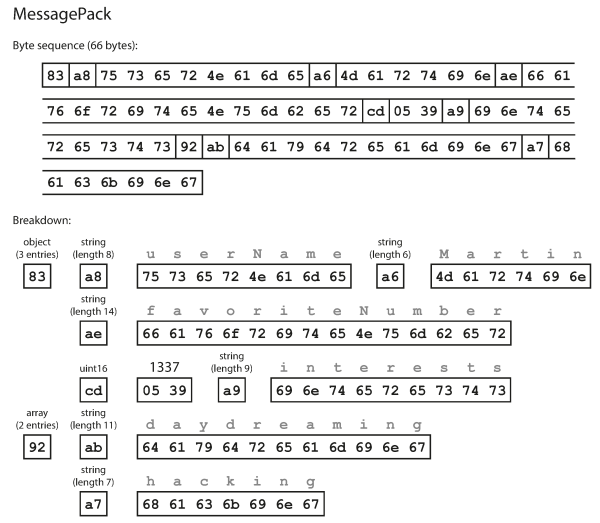
An example of MessagePack encoding from a JSON format:
{ "userName": "Martin", "favoriteNumber": 1337, "interests": ["daydreaming", "hacking"] }
Thrift and Protocol Buffers
Both Thrift and Protocol Buffers require a schema for any data that is encoded.
Thrift and Protocol Buffers each come with a code generation tool that takes a schema definition, and produces classes that implement the schema in various programming languages. Your application code can call this generated code to encode or decode records of the schema.
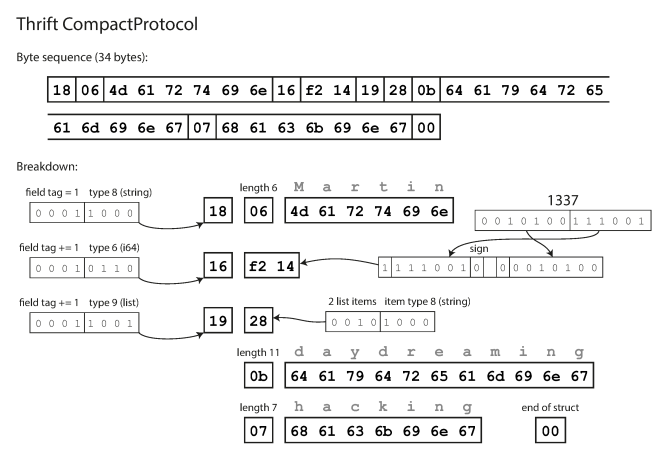
Thrift interface definition language (IDL) is like this :
struct Person { 1: required string userName, 2: optional i64 favoriteNumber, 3: optional list<string> interests }
How Thrift and Protocol Buffers handle schema changes while keeping backward and forward compatibility
An encoded record is just the concatenation of its encoded fields.
Each field is identified by its tag number and annotated with a datatype (e.g., string or integer). If a field value is not set, it is simply omitted from the encoded record. From this, we can see that field tags are critical to the meaning of the encoded data. we can change the name of a field in the schema since the encoded data never refers to field names, but we cannot change a field’s tag, since that would make all existing encoded data invalid.As long as each field has a unique tag number, new code can always read old data, because the tag numbers still have the same meaning.
Removing a field is just like adding a field, with backward and forward compatibility concerns reversed.
Protocol Buffers is that it does not have a list or array datatype, but instead has a
repeatedmarker for fields (which is a third option alongsiderequiredandoptional).Thrift has a dedicated list datatype, which is parameterized with the data type of the list elements.
Avro
- Avro also uses a schema to specify the structure of the data being encoded. It has two schema languages:
- (Avro IDL) intended for human editing.
The other one (based on JSON) is more easily machine-readable.
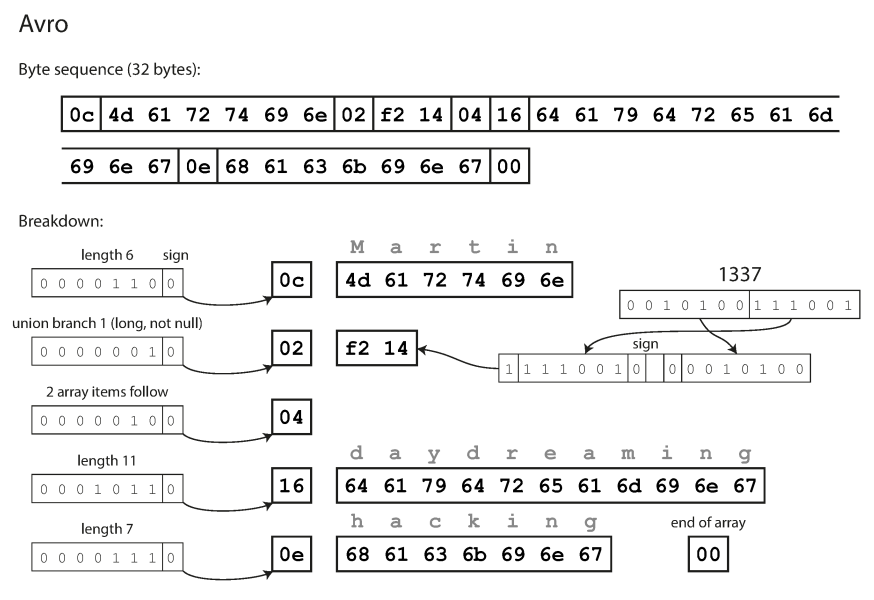
Example schema, written in Avro IDL :
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
With Avro, when an application wants to encode some data it encodes the data using whatever version of the schema it knows about. For example, that schema may be compiled into the application. This is known as the writer’s schema.
When an application wants to decode some data, it is expecting the data to be in some schema, which is known as the reader’s schema.
The key idea with Avro is that the writer’s schema and the reader’s schema don’t have to be the same. They only need to be compatible.
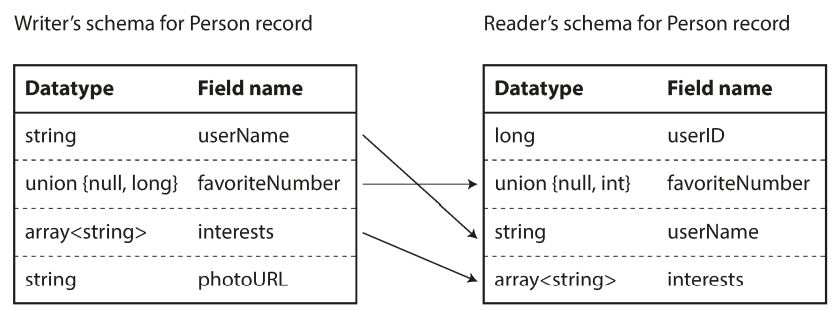
In Avro: if you want to allow a field to be null, you have to use a
uniontype. For example :union { null, long, string } field;indicates that field can be a number, a string, or null.
Avro doesn’t have
optionalandrequiredmarkers in the same way as Protocol Buffers and Thrift do.Changing a field name is backward compatible but not forward compatible.
Database of schema versions is a useful thing to have in any case, since it acts as documentation and gives you a chance to check schema compatibility. As the version number, you could use a simple incrementing integer, or you could use a hash of the schema.
Thrift and Protocol Buffers rely on code generation: after a schema has been defined, you can generate code that implements this schema in a programming language of our choice.
In dynamically typed programming languages such as JavaScript, Ruby, or Python, there is not much point in generating code, since there is no compile-time type checker to satisfy. Code generation is often frowned upon in these languages since they otherwise avoid an explicit compilation step.
The Merits of Schemas
Protocol Buffers, Thrift, and Avro all use a schema to describe a binary encoding format. Their schema languages are much simpler than XML Schema or JSON Schema, which support much more detailed validation rules.
Most relational databases have a network protocol over which you can send queries to the database and get back responses.
Good Properties of JSON, XML, and CSV
• They can be much more compact than the various “binary JSON” variants.
• The schema is a valuable form of documentation, and you can be sure that it is up to date.
• Keeping a database of schemas allows you to check the forward and backward compatibility of schema changes before anything is deployed.
• For users of statically typed programming languages, the ability to generate code from the schema is useful since it enables type checking at compile time.
Modes of Dataflow
Dataflow Through Databases
In a database, the process that writes to the database encodes the data, and the process that reads from the database decodes it.
in an environment where the application is changing, it is likely that some processes accessing the database will be running newer code and some will be running older code. Thus, forward compatibility is also often required for databases.
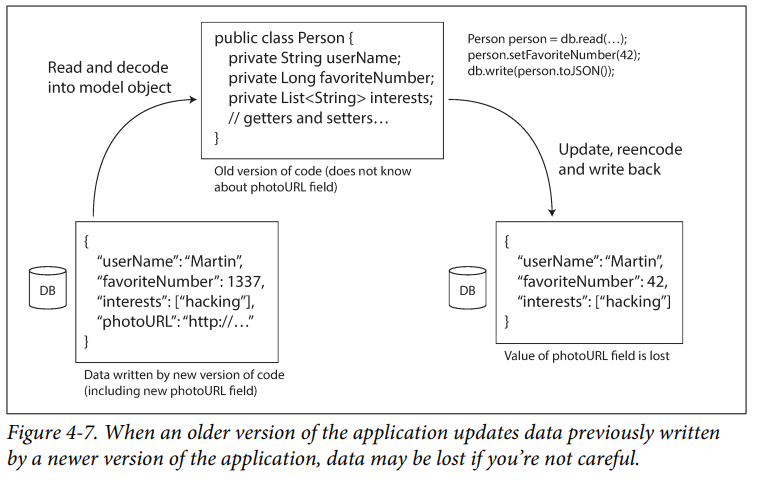
Rewriting (migrating) data into a new schema is certainly possible, but it’s an expensive thing to do on a large dataset, so most databases avoid it if possible. Most relational databases allow simple schema changes, such as adding a new column with a
nulldefault valueWe can take a snapshot of your database from time to time, say for backup purposes or for loading into a data warehouse. In this case, the data dump will typically be encoded using the latest schema, even if the original encoding in the source database contained a mixture of schema versions from different eras.
Dataflow Through Services: REST and RPC
When you have processes that need to communicate over a network, there are a few different ways of arranging that communication. The most common arrangement is to have two roles: clients and servers. The servers expose an API over the network, and the clients can connect to the servers to make requests to that API. The API exposed by the server is known as a service.
When one service makes a request to another when it requires some functionality or data from another service. This way of building applications has traditionally been called a service-oriented architecture (SOA), more recently refined and rebranded as microservices architecture
A key design goal of a service-oriented/microservices architecture is to make the application easier to change and maintain by making services independently deployable and evolvable.
REST is not a protocol, but rather a design philosophy that builds upon the principles of HTTP. It emphasizes simple data formats, using URLs for identifying resources and using HTTP features for cache control, authentication, and content type negotiation.
SOAP is an XML-based protocol for making network API requests.
The API of a SOAP web service is described using an XML-based language called the Web Services Description Language, or "WSDL".
WSDL is not designed to be human-readable, and as SOAP messages are often too complex to construct manually, users of SOAP rely heavily on tool support, code generation, and IDEs
Differences Between a Network Request and a Local Function Call
A local function call is predictable and either succeeds or fails, depending only on parameters that are under your control. A network request is unpredictable: the request or response may be lost due to a network problem.
A local function call either return a result, or throws an exception, or never returns. A network request has another possible outcome: it may return without a result, due to a timeout.
Every time you call a local function, it normally takes about the same time to execute. A network request is much slower than a function call, and its latency is also wildly variable.
When calling a local function, you can efficiently pass its references (pointers) to objects in local memory. But when you make a network request, all those parameters need to be encoded into a sequence of bytes that can be sent over the network.
There’s no point trying to make a remote service look too much like a local object in your programming language, because it’s a fundamentally different thing.
This new generation of RPC frameworks is more explicit about the fact that a remote request is different from a local function call.
REST seems to be the predominant style for public APIs. The main focus of RPC frameworks is on requests between services owned by the same organization, typically within the same data centre.
Message-Passing Dataflow
Advantages of Using a Message Broker
• It can act as a buffer if the recipient is unavailable or overloaded, and thus improve system reliability.
• It can automatically redeliver messages to a process that has crashed, and thus prevent messages from being lost.
• It avoids the sender needing to know the IP address and port number of the recipient (which is particularly useful in a cloud deployment where virtual machines often come and go).
• It allows one message to be sent to several recipients.
• It logically decouples the sender from the recipient.
The actor model is a programming model for concurrency in a single process. Rather than dealing directly with threads, logic is encapsulated in actors. Each actor typically represents one client or entity, it may have some local state, and it communicates with other actors by sending and receiving asynchronous messages.
Location transparency works better in the actor model than in RPC, because the actor model already assumes that messages may be lost, even within a single process.
Asynchronous message passing using message brokers or actors, where nodes communicate by sending each other messages that are encoded by the sender and decoded by the recipient needs data encodings.
Thank you, and goodbye!




