Designing Data Intensive Applications - Chapter 5
Book Summary

Replication means keeping a copy of the same data on multiple machines that are connected via a network.
Reasons Why You Might Want to Replicate Data
• To keep data geographically close to your users. • To allow the system to continue working even if some of its parts have failed. • To scale out the number of machines that can serve read queries (and thus increase read throughput).
Leaders and Followers
- Each node that stores a copy of the database is called a replica.
Three Main Approaches to Replication
- Single-leader replication
- Multi-leader replication
Leaderless replication
Leader-based replication is a solution to the problem that every write to the database needs to be processed by every replica; otherwise, the replicas would no longer contain the same data.
How Leader-Based Replication Works
- One of the replicas is designated the leader (also known as master or primary). When clients want to write to the database, they must send their requests to the leader, which first writes the new data to its local storage.
- Whenever the leader writes new data to its local storage, it also sends the data change to all of its followers as part of a replication log or change stream.
- When a client wants to read from the database, it can query either the leader or any of the followers.
Setting Up New Followers
Take a consistent snapshot of the leader’s database at some point in time if possible, without taking a lock on the entire database. Most databases have this feature, as it is also required for backups.
Copy the snapshot to the new follower node.
The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken.
When the follower has processed the backlog of data changes since the snapshot, we say it has caught up. It can now continue to process data changes from the leader as they happen.
Handling Node Outages
- Being able to reboot individual nodes without downtime is a big advantage for operations and maintenance.
- Followers can connect to the leader and request all the data changes that occurred during the time when the followers were disconnected.
- Handling a failure of the leader is trickier as one of the followers needs to be promoted to be the new leader, clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover.
Automatic Failover Process Steps
- Determining that the leader has failed.
- Choosing a new leader.
- Reconfiguring the system to use the new leader.
Failover Problems
- If asynchronous replication is used, the new leader may not have received all the writes from the old leader before it failed.
- Discarding writes is especially dangerous if other storage systems outside of the database need to be coordinated with the database contents.
- In certain fault scenarios, it could happen that two nodes both believe that they are the leader. This situation is called split brain.
- If the system is already struggling with high load or network problems, an unnecessary failover is likely to make the situation worse, not better.
Implementation of Replication Logs
- In the simplest case, the leader logs every write request that it executes and sends that statement log to its followers. This approach has some problems :
Functions like
NOW(), andRAND()are likely to generate a different value on each replica.If statements use an autoincrementing column, or if they depend on the existing data in the database, they must be executed in exactly the same order on each replica, or else they may have a different effect.
Statements that have side effects (e.g., triggers, stored procedures, user-defined functions) may result in different side effects occurring on each replica.
Logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row :
• For an inserted row, the log contains the new values of all columns.
• For a deleted row, the log contains enough information to uniquely identify the row that was deleted. Typically this would be the primary key, but if there is no primary key on the table, the old values of all columns need to be logged.
• For an updated row, the log contains enough information to uniquely identify the updated row, and the new values of all columns.
- Trigger lets you register custom application code that is automatically executed when a data change (write transaction) occurs in a database system. The trigger has the opportunity to log this change into a separate table, from which it can be read by an external process.
Problems with Replication Lag
Leader-based replication requires all writes to go through a single node, but read-only queries can go to any replica. For workloads that consist of mostly reads and only a small percentage of writes.
read-scaling architecture is when you can increase the capacity for serving read-only requests simply by adding more followers. This approach only realistically works with asynchronous replication.
- If an application reads from an asynchronous follower, it may see out‐ dated information if the follower has fallen behind.
Reading Your Own Writes
- With asynchronous replication, there is a problem that if the user views the data shortly after making a write, the new data may not yet have reached the replica. To the user, it looks as though the data they submitted was lost In this situation, we need read-after write consistency, also known as read-your-writes consistency.
Implementing Techniques for Read-After-Write Consistency in a System With Leader-Based Replication
When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower.
The client can remember the timestamp of its most recent write—then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. If a replica is not sufficiently up to date, either the read can be handled by another replica or the query can wait until the replica has caught up.
If your replicas are distributed across multiple datacenters, there is additional complexity. Any request that needs to be served by the leader must be routed to the data centre that contains the leader.
Monotonic Reads
Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency. When you read data, you may see an old value; monotonic reads only mean that if one user makes several reads in sequence, they will not see time go backward.
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica.
Consistent Prefix Reads
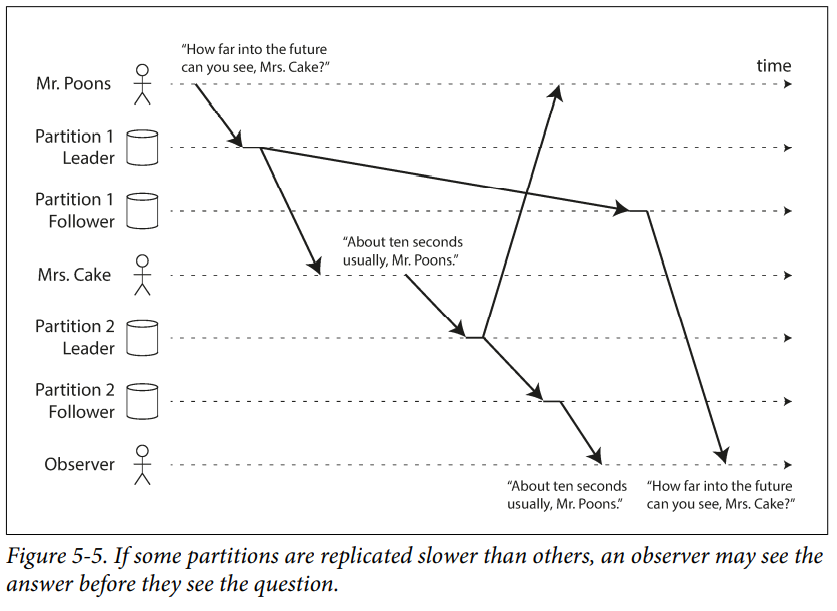
One solution is to make sure that any writes that are causally related to each other are written to the same partition.
Transactions are a way for a database to provide stronger guarantees so that the application can be simpler.
Multi-Leader Replication
Leader-based replication has one major downside which is that there is only one leader, and all writes must go through it.iv If you can’t connect to the leader for any reason, for example due to a network interruption between you and the leader, you can’t write to the database.
A natural extension of the leader-based replication model is to allow more than one node to accept writes.
Use Cases for Multi-Leader Replication
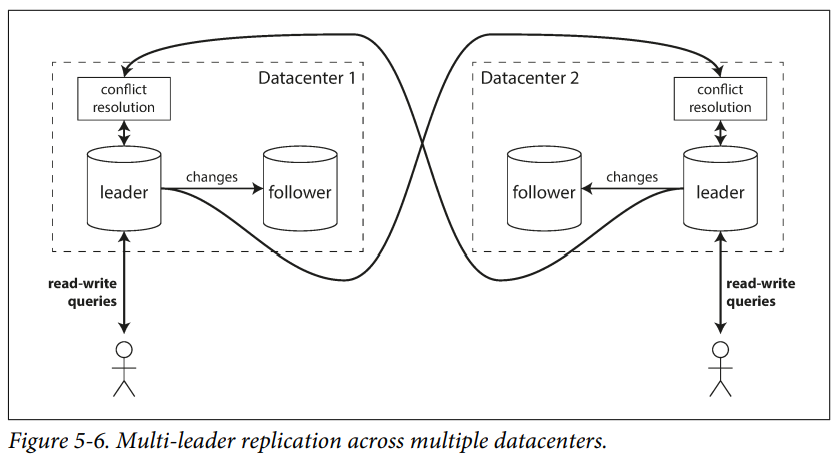
How Single-Leader and Multi-Leader Configurations Fare in a Multi-Datacenter Deployment
Performance : In a single-leader configuration, every write must go over the internet to the data centre with the leader. This can add significant latency to writes and might contravene the purpose of having multiple data centres in the first place. In a multi-leader configuration, every write can be processed in the local datacenter and is replicated asynchronously to the other datacenters.
Tolerance of data centre outages : In a single-leader configuration if the data centre with the leader fails, failover can promote a follower in another data centre to be leader. In a multi-leader configuration, each data centre can continue operating independently of the others, and replication catches up when the failed data centre comes back online.
Tolerance of network problems : A single-leader configuration is very sensitive to problems in this inter-datacenter link because writes are made synchronously over this link. A multi-leader configuration with asynchronous replication can usually tolerate network problems better: a temporary network interruption does not prevent writes from being processed.
Multi-leader replication is a somewhat retrofitted feature in many databases. Though multi-leader replication is often considered dangerous territory that should be avoided if possible.
Multi-leader replication is appropriate is if you have an application that needs to continue to work while it is disconnected from the internet.
Real-time collaborative editing applications allow several people to edit a document simultaneously. Such as "Google Docs".
If you want to guarantee that there will be no editing conflicts, the application must obtain a lock on the document before a user can edit it. If another user wants to edit the same document, they first have to wait until the first user has committed their changes and released the lock.
Handling Write Conflicts

We could make the conflict detection synchronous waiting for the write to be replicated to all replicas before telling the user that the write was successful. But we would lose allowing each replica to accept writes independently.
The simplest strategy for dealing with conflicts is to avoid them.
Single-leader database applies writes in sequential order : if there are several updates to the same field, the last write determines the final value of the field.
Ways of Achieving Convergent Conflict Resolution
- Give each write a unique ID, then pick the write with the highest ID as the winner, and throw away the other writes. If a timestamp is used, this technique is known as last write wins (LWW).
- Give each replica a unique ID, and let writes that originated at a higher-numbered replica always take precedence overwrites that originated at a lower-numbered replica.
- Somehow merge the values together, order them alphabetically and then concatenate them.
Record the conflict in an explicit data structure that preserves all information, and write application code that resolves the conflict at some later time.
Conflict-free replicated datatypes (CRDTs) are a family of data structures for sets, maps, ordered lists, counters, etc. that can be concurrently edited by multiple users, and which automatically resolve conflicts in sensible ways.
Operational transformation is the conflict resolution algorithm behind collaborative editing applications such as Etherpad and Google Docs.
Multi-Leader Replication Topologies
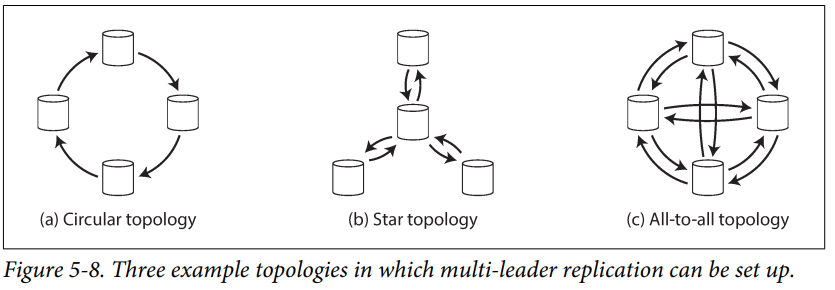
Replication topology describes the communication paths along which writes are propagated from one node to another. The most general topology is all-to-all.
MySQL by default supports only "circular topology", in which each node receives writes from one node and forwards those writes to one other node.
A problem with circular and star topologies is that if just one node fails, it can interrupt the flow of replication messages between other nodes, causing them to be unable to communicate until the node is fixed.
Leaderless Replication
- Some data storage systems (including some of the earliest replicated data systems) take a different approach, abandoning the concept of a leader and allowing any replica to directly accept writes from clients.
Mechanisms Often Used in Dynamo-style Datastores
- Read repair : when a client makes a read from several nodes in parallel, it can detect any stale (outdated) responses.
Writing to the Database When a Node Is Down
Anti-entropy process : when some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another.
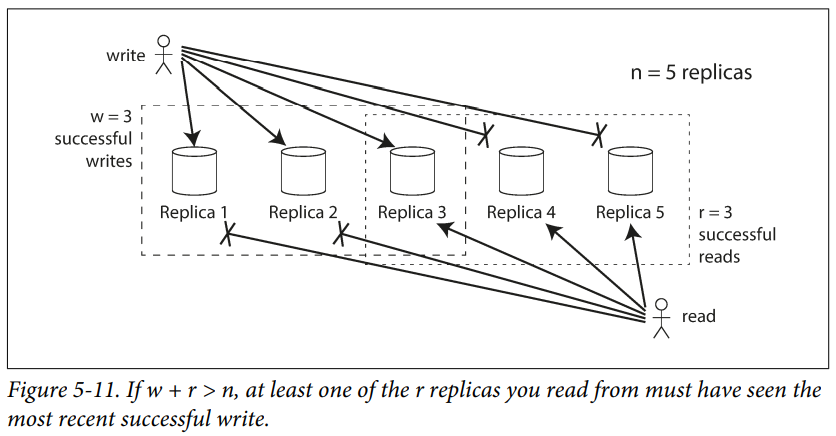
randware the minimum numbers of votes required for the reading or writing to be valid. They are called "quorum reads" and "quorum writes" respectively.The quorum condition,
w + r > n, allows the system to tolerate unavailable nodes as follows :
• Ifw < n, we can still process writes if a node is unavailable.
• Ifr < n, we can still process reads if a node is unavailable.
• With n = 3, w = 2, r = 2 we can tolerate one unavailable node.
• With n = 5, w = 3, r = 3 we can tolerate two unavailable nodes.
• Normally, reads and writes are always sent to allnreplicas in parallel. The parameterswandrdetermine how many nodes we wait for.
Limitations of Quorum Consistency
- Even with w + r > n, there are likely to be edge cases where stale values are returned :
- If a sloppy quorum is used
- If two writes occur concurrently, it is not clear which one happened first. As If a winner is picked based on a timestamp, writes can be lost due to clock skew.
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas.
- If a write was reported as failed, subsequent reads may or may not return the value from that write.
Sloppy Quorums and Hinted Handoff
-Sloppy quorum : is when writes and reads still require w and r successful responses, but those may include nodes that are not among the designated. Sloppy quorums are particularly useful for increasing write availability as long as any w nodes are available, the database can accept writes.
Sloppy quorums are optional in all common Dynamo implementations.
Network interruption can easily cut off a client from a large number of database nodes. Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes. This is called hinted handoff.
Detecting Concurrent Writes
It may seem that two operations should be called concurrent if they occur “at the same time” but in fact, it is not important whether they literally overlap in time. Because of problems with clocks in distributed systems, it is actually quite difficult to tell whether two things happened at exactly the same time.
In computer systems, two operations might be concurrent even though the speed of light would in principle have allowed one operation to affect the other.
Algorithm Steps to Determine Whether Two Operations are Concurrent or Not
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written.
- When a client reads a key, the server returns all values that have not been over-written, as well as the latest version number. A client must read a key before writing.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read.
- When the server receives a write with a particular version number, it can over-write all values with that version number or below, but it must keep all values with a higher version number.
- The collection of version numbers from all the replicas is called a version vector. It allows the database to distinguish between overwrites and concurrent writes.
Thank you, and goodbye!




