Designing Data Intensive Applications - Chapter 6
Book Summary

Partitioning and Replication
- We have to know that "partition" = "shard"
- The main reason for wanting to partition data is scalability. As a large dataset can be distributed across many disks, and the query load can be distributed across many processors.
- The choice of partitioning scheme is mostly independent of the choice of replication scheme.
Partitioning of Key-Value Data
- If the partitioning is unfair, so that some partitions have more data or queries than others, we call it skewed.
- A partition with a disproportionately high load is called a hot spot.
Partitioning by Key Range
- One way of partitioning is to assign a continuous range of keys (from some minimum to some maximum) to each partition. The ranges of keys are not necessarily evenly spaced, because your data may not be evenly distributed.

The partition boundaries might be chosen manually by an administrator, or the data base can choose them automatically.
the downside of key range partitioning is that certain access patterns can lead to hot spots if the key is a timestamp for example.
Partitioning by Hash of Key
Many distributed datastores use a hash function to determine the partition for a given key.
A good hash function takes skewed data and makes it uniformly distributed.
Once we have a suitable hash function for keys, you can assign each partition a range of hashes (rather than a range of keys), and every key whose hash falls within a partition’s range will be stored in that partition.
Consistent Hashing
Consistent hashing is a way of evenly distributing the load across an internet-wide system of caches such as CDN.
It uses randomly chosen partition boundaries to avoid the need for central control or distributed consensus.
- by using the hash of the key for partitioning we lose the ability to do efficient range queries.
Skewed Workloads and Relieving Hot Spots
- Most data systems are not able to automatically compensate for such a highly skewed workload.
Partitioning and Secondary Indexes
Secondary indexes are the bread and butter of relational databases, and they are common in document databases too.
The problem with secondary indexes is that they don’t map neatly to partitions.
The Main Approaches to Partitioning a Database with Secondary Indexes
- document-based partitioning.
- term-based partitioning.
Partitioning Secondary Indexes by Document
Document-partitioned index is also known as a local index.
In this indexing approach, each partition is completely separate: each partition maintains its own secondary indexes, covering only the documents in that partition. It doesn’t care what data is stored in other partitions. Whenever you need to write to the database, to add, remove, or update a document you only need to deal with the partition that contains the document
IDthat you are writing.
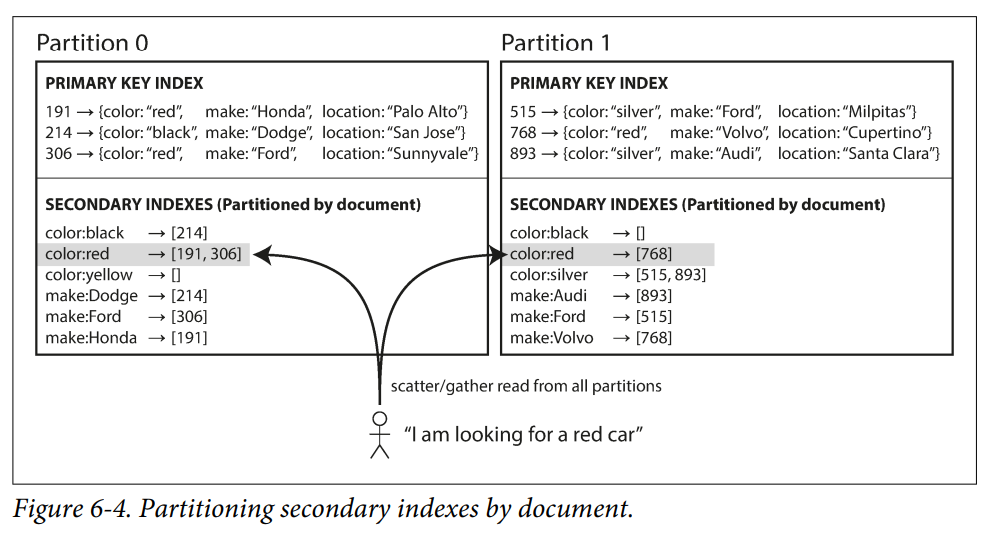
This approach to querying a partitioned database is sometimes known as scatter / gather.
Most database vendors recommend that you structure your partitioning scheme so that secondary index queries can be served from a single partition.

Partitioning Secondary Indexes by Term
Rather than each partition having its own secondary index (a local index), we can construct a global index that covers data in all partitions.
We can partition the index by the term itself, or using a hash of the term. Partitioning by the term itself can be useful for range scans whereas partitioning on a hash of the term gives a more even distribution of load.
The advantage of a global (term-partitioned) index over a document-partitioned index is that it can make reads more efficient: rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants.
The downside of a global index is that writes are slower and more complicated.
In practice, updates to global secondary indexes are often asynchronous.
Rebalancing Partitions
Minimum Requirements for Rebalancing
- After rebalancing, the load should be shared fairly between the nodes in the cluster.
- While rebalancing is happening, the database should continue accepting reads and writes.
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
Strategies for Rebalancing
Hash Mod N
- The problem with the mod N approach is that if the number of nodes
Nchanges, most of the keys will need to be moved from one node to another. Such frequent moves make rebalancing excessively expensive.
Fixed Number of Partitions
- The solution is to create many more partitions than there are nodes, and assign several partitions to each node.
- If a node is added to the cluster, the new node can steal a few partitions from every existing node until partitions are fairly distributed once again.
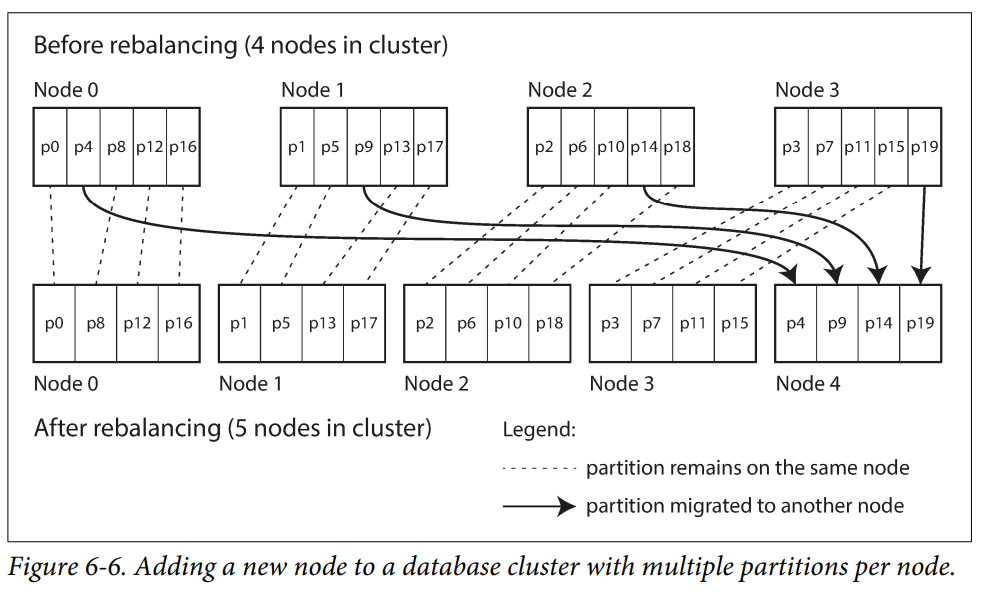
Choosing the right number of partitions is difficult if the total size of the dataset is highly variable.
Since each partition contains a fixed fraction of the total data, the size of each partition grows proportionally to the total amount of data in the cluster.
If partitions are very large, rebalancing and recovery from node failures become expensive.
Dynamic Partitioning
When a partition grows to exceed a configured size, it is split into two partitions so that approximately half of the data ends up on each side of the split.
After a large partition has been split, one of its two halves can be transferred to another node in order to balance the load.
If lots of data is deleted and a partition shrinks below some threshold, it can be merged with an adjacent partition.
An advantage of dynamic partitioning is that the number of partitions adapts to the total data volume.
In the case of key-range partitioning, pre-splitting requires that you already know what the key distribution is going to look like.
Partitioning proportionally to nodes
- We can make the number of partitions proportional to the number of nodes. So to have a fixed number of partitions per node. In this case, the size of each partition grows proportionally to the dataset size while the number of nodes remains unchanged, but when you increase the number of nodes, the partitions become smaller again.
- Picking partition boundaries randomly requires that hash-based partitioning is used.
Operations: Automatic or Manual Rebalancing
Fully automated rebalancing can be convenient but, it can be unpredictable. Rebalancing is an expensive operation because it requires rerouting requests and moving a large amount of data from one node to another.
it can be a good thing to have a human in the loop for rebalancing. It’s slower than a fully automatic process, but it can help prevent operational surprises.
Request Routing
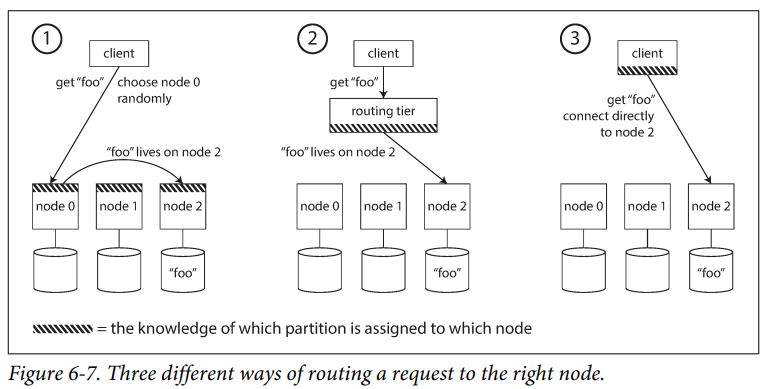
There are a few different approaches to this problem
Allow clients to contact any node. If that node coincidentally owns the partition to which the request applies, it can handle the request directly; otherwise, it forwards the request to the appropriate node, receives the reply, and passes the reply along to the client.
Send all requests from clients to a routing tier first, which determines the node that should handle each request and forwards it accordingly. This routing tier does not itself handle any requests; it only acts as a partition-aware load balancer.
Require that clients be aware of the partitioning and the assignment of partitions to nodes. In this case, a client can connect directly to the appropriate node, without any intermediary.
Many distributed data systems rely on a separate coordination service such as ZooKeeper to keep track of this cluster metadata.
Gossip protocol among the nodes to disseminate any changes in the cluster state. Requests can be sent to any node, and that node forwards them to the appropriate node for the requested partition. This model puts more complexity in the database nodes but avoids the dependency on an external coordination service such as ZooKeeper.
Parallel Query Execution
- A typical data warehouse query contains several join, filtering, grouping, and aggregation operations.
- The massively parallel processing (MPP) query optimizer breaks this complex query into a number of execution stages and partitions, many of which can be executed in parallel on different nodes of the database cluster.
Thank you, and goodbye!




