Designing Data Intensive Applications - Chapter 7
Book Summary

- Transaction is a way for an application to group several reads and writes together into a logical unit.
By using transactions, the application is free to ignore certain potential error scenarios and concurrency issues, because the database takes care of them instead (we call these safety guarantees).
Not every application needs transactions, and sometimes there are advantages to weakening transactional guarantees.
The Slippery Concept of a Transaction
The Meaning of ACID
The safety guarantees provided by transactions are often described by the well-known acronym "ACID", which stands for Atomicity, Consistency, Isolation, and Durability.
"Atomic" refers to something that cannot be broken down into smaller parts. The word means similar but subtly different things in different branches of computing.
in the context of ACID, atomicity is not about concurrency. It does not describe what happens if several processes try to access the same data at the same time.
ACID atomicity describes what happens if a client wants to make several writes, but a fault occurs after some of the writes have been processed.
The idea of consistency depends on the application’s notion of invariants.
Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application.
Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other.
- Durability is the promise that once a transaction has been committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
Single-Object and Multi-Object Operations
- Multi-object transactions require some way of determining which read and write operations belong to the same transaction. In relational databases, that is typically done based on the client’s TCP connection to the database server.
Atomicity can be implemented using a log for crash recovery, and isolation can be implemented using a lock on each object.
A key feature of a transaction is that it can be aborted and safely retried if an error occurred
ACID databases are based on this philosophy: if the database is in danger of violating its guarantee of atomicity, isolation, or durability, it would rather abandon the transaction entirely than allow it to remain half-finished.
Drawbacks of Retrying an Aborted Transaction
If the error is due to overload, retrying the transaction will make the problem worse, not better.
It is only worth retrying after transient errors after a permanent error (e.g., constraint violation) a retry would be pointless.
If the client process fails while retrying, any data it was trying to write to the database is lost.
Weak Isolation Levels
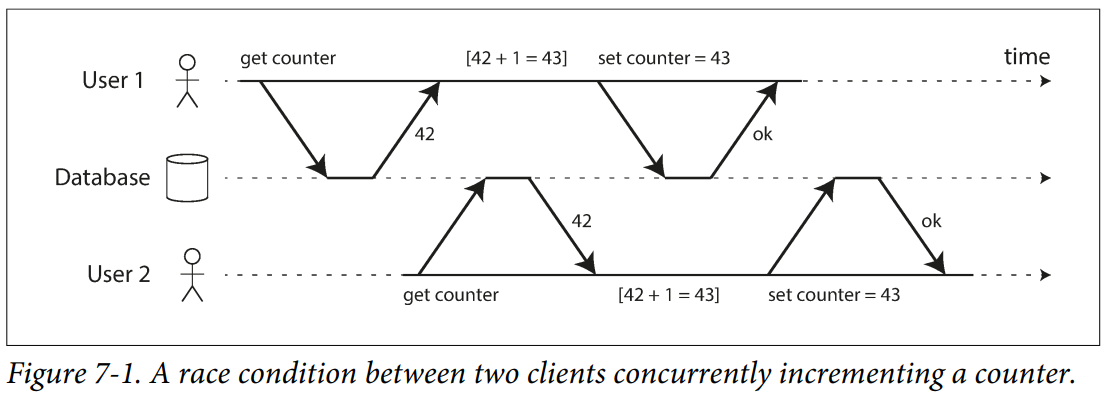
Concurrency issues (race conditions) only come into play when one transaction reads data that is concurrently modified by another transaction, or when two transactions try to simultaneously modify the same data.
Databases have long tried to hide concurrency issues from application developers by providing transaction isolation.
- Serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially.
Read Committed
The Most Basic Level of Transaction Isolation :
- When reading from the database, you will only see data that has been committed.
- When writing to the database, you will only overwrite data that has been committed.
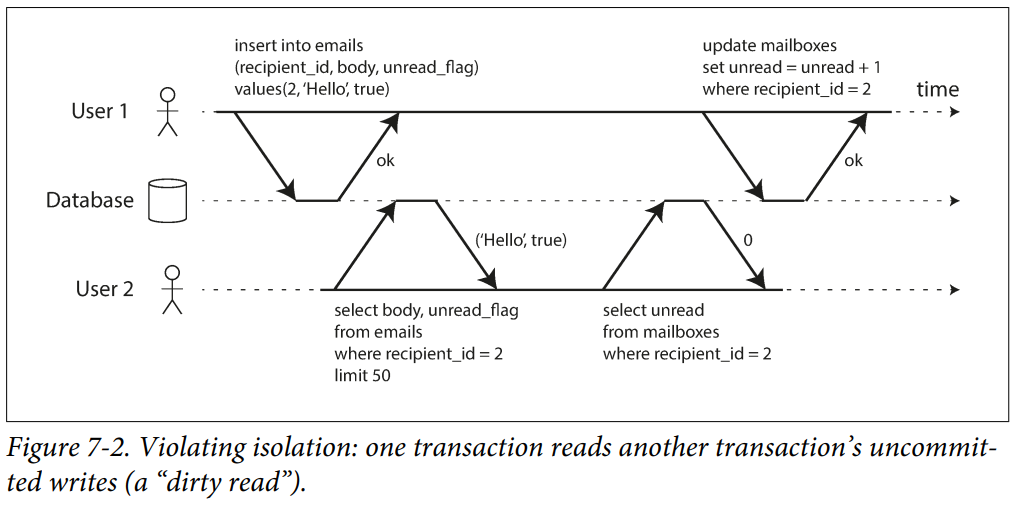
Reasons to Prevent Dirty Reads
- If a transaction needs to update several objects, a dirty read means that another transaction may see some of the updates but not others.
- Ia transaction aborts, any writes it has made need to be rolled back. If the database allows dirty reads, that means a transaction may see data that is later rolled back.
- Most databases prevent dirty reads using this approach as for every object that is written, the database remembers both the old com‐ mitted value and the new value set by the transaction that currently holds the write lock. While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
Snapshot Isolation and Repeatable Read
Situations Cannot Tolerate Temporary Inconsistency
Backups as you could end up with some parts of the backup containing an older version of the data, and other parts containing a newer version.
Analytic queries and integrity checks as sometimes, you may want to run a query that scans over large parts of the database.
Snapshot Isolation is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time.
A key principle of snapshot isolation is readers never block writers, and writers never block readers.
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object: the committed version and the overwritten-but-not-yet-committed version.
How The Database Can Present a Consistent Snapshot of The Database to The Application
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit.
- Any writes made by aborted transactions are ignored.
- Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have been committed.
All other writes are visible to the application’s queries.
Many implementation details determine the performance of multi-version concurrency control.
Snapshot isolation is a useful isolation level, especially for read-only transactions.
Preventing Lost Updates
The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification.
Cursor stability is when atomic operations are usually implemented by taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied.
Atomic operations can work well in a replicated context, especially if they are commutative. For example, incrementing a counter or adding an element to a set are commutative operations.
Write Skew and Phantoms
Write skew is a generalization of the lost update problem.
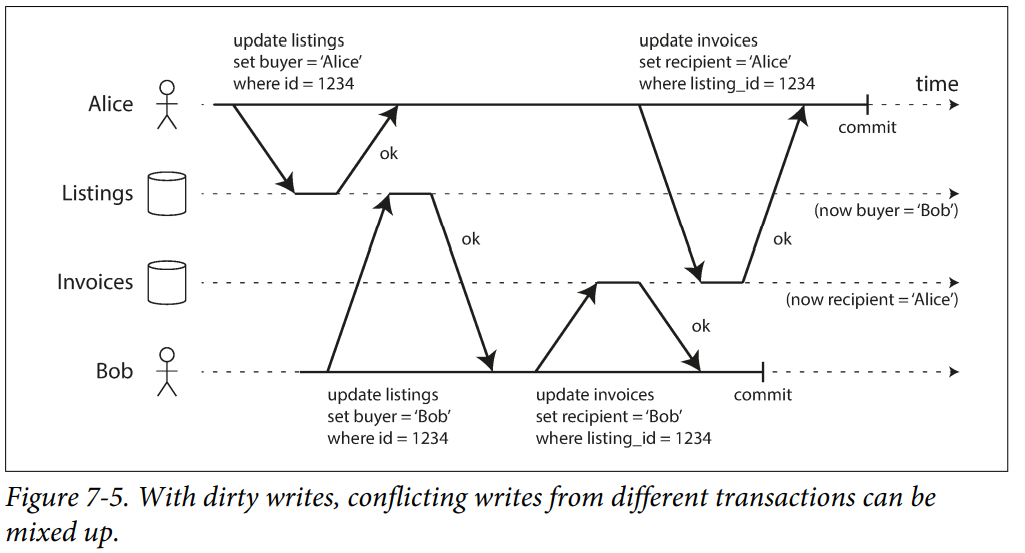
Write skew can occur if two transactions read the same objects, and then update some of those objects. In the special case where different transactions update the same object, you get a dirty write or lost update anomaly.
An example, in a multiplayer game we use a lock to prevent lost updates. However, the lock doesn’t prevent players from moving two different figures to the same position on the board or potentially making some other move that violates the rules of the game. Depending on the kind of rule you are enforcing, you might be able to use a unique constraint, but otherwise, you’re vulnerable to write skew.
The effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom.
Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions.
Materializing conflicts is when we take a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database. A serializable isolation level is much preferable in most cases.
Isolation levels protect against some of those anomalies but leave you, the application developer, to handle others manually. Only serializable isolation protects against all of these issues.
Serializability
Isolation levels are hard to understand, and inconsistently implemented in different databases.
If you look at your application code, it’s difficult to tell whether it is safe to run at a particular isolation level, especially in a large application.
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency.
Techniques That Databases Use to Provide Serializability
- Literally executing transactions in a serial order.
- Two-phase locking, which for several decades was the only viable option.
- Optimistic concurrency control techniques such as serializable snapshot isolation.
Actual Serial Execution
The simplest way of avoiding concurrency problems is to remove the concurrency entirely.
The approach of executing transactions serially is implemented in VoltDB/H-Store, and Redis.
A system designed for single-threaded execution can sometimes perform better than a system that supports concurrency.
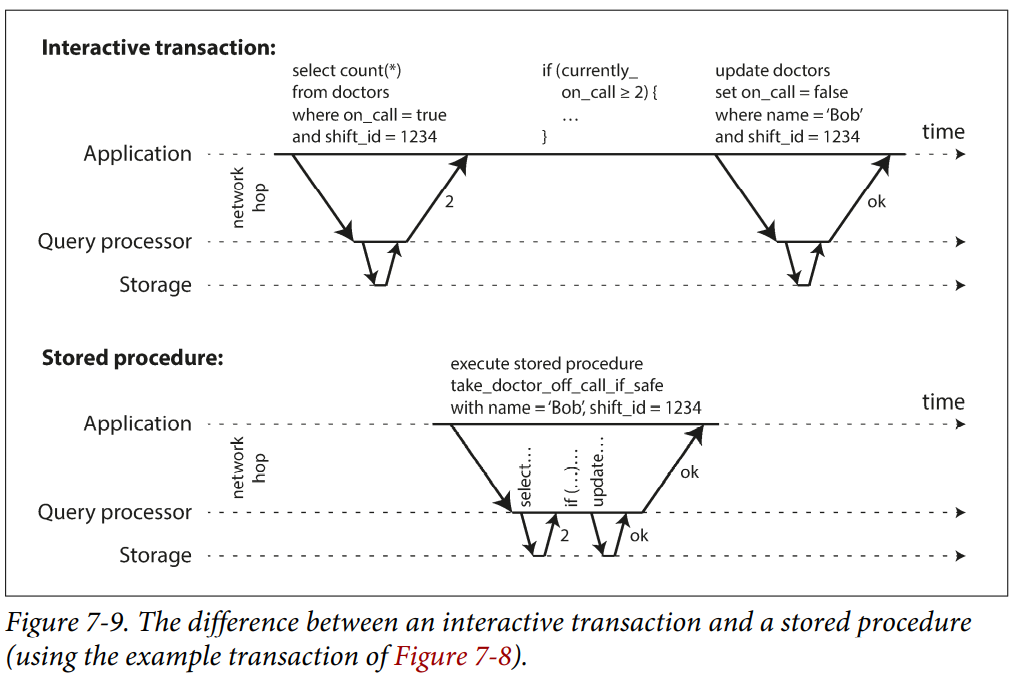
If you were to disallow concurrency in the database and only process one transaction at a time, the throughput would be dreadful because the database would spend most of its time waiting for the application to issue the next query for the current transaction.
Systems with single-threaded serial transaction processing don’t allow interactive multi-statement transactions. Instead, the application must submit the entire transaction code to the database ahead of time, as a stored procedure.
Cons of Stored Procedures
Code running in a database is difficult to manage.
badly written stored procedure in a database can cause much more trouble than equivalent badly written code in an application server.
Executing all transactions serially makes concurrency control much simpler, but lim‐ its the transaction throughput of the database to the speed of a single CPU core on a single machine.
Whether transactions can be single-partition depends very much on the structure of the data used by the application. Simple key-value data can often be partitioned very easily, but data with multiple secondary indexes is likely to require a lot of cross-partition coordination.
Two-Phase Locking (2PL)
It is a widely used algorithm for serializability in databases.
Snapshot isolation has the mantra readers never block writers, and writers never block readers which captures this key difference between snapshot isolation and two-phase locking.
The big downside of two-phase locking is the performance: as transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation. This is partly due to the overhead of acquiring and releasing all those locks, but more importantly due to reduced concurrency.
Databases running 2PL can have quite unstable latencies, and they can be very slow at high percentiles if there is contention in the workload.
Most databases with 2PL actually implement index-range locking, which is a simplified approximation of predicate locking.
Serializable Snapshot Isolation (SSI)
- Two-phase locking is a so-called pessimistic concurrency control mechanism: it is based on the principle that if anything might possibly go wrong, it’s better to wait until the situation is safe again before doing anything. It is like mutual exclusion, which is used to protect data structures in multi-threaded programming.
Serializable snapshot isolation is an optimistic concurrency control technique. Optimistic in this context means that instead of blocking if something potentially dangerous happens, transactions continue anyway, in the hope that everything will turn out all right. When a transaction wants to commit, the database checks whether anything bad happened (i.e., whether isolation was violated); if so, the transaction is aborted and has to be retried. Only transactions executed serializably are allowed to commit.
SSI is based on snapshot isolation that is, all reads within a transaction are made from a consistent snapshot of the database.
Ways by which The Database Knows if a Query Result Might Have Changed
Detecting reads of a stale MVCC object version.
Detecting writes that affect prior reads (the write occurs after the read.
Compared to serial execution, serializable snapshot isolation is not limited to the throughput of a single CPU core.
Thank you, and goodbye!




