Designing Data Intensive Applications - Chapter 8
Book Summary

Faults and Partial Failures
- An individual computer with good software is usually either fully functional or entirely broken, but not something in between.
If an internal fault occurs, we prefer a computer to crash completely rather than returning a wrong result, because wrong results are difficult and confusing to deal with.
The non-determinism and possibility of partial failures are what make distributed systems hard to work with.
Cloud Computing and Supercomputing
Philosophies on How to Build Large-scale Computing Systems
At one end of the scale is the field of high-performance computing (HPC). Supercomputers with thousands of CPUs are typically used for computationally intensive scientific computing tasks, such as weather forecasting or molecular dynamics.
At the other extreme is cloud computing, which is not very well defined but is often associated with multi-tenant datacenters, commodity computers connected with an IP network (often Ethernet), elastic/on-demand resource allocation, and metered billing.
Traditional enterprise datacenters lie somewhere between these extremes.
Supercomputers are typically built from specialized hardware, where each node is quite reliable, and nodes communicate through shared memory and remote direct memory access (RDMA).
If we want to make distributed systems work, we must accept the possibility of partial failure and build fault-tolerance mechanisms into the software.
It would be unwise to assume that faults are rare and simply hope for the best. It is important to consider a wide range of possible faults even fairly unlikely ones.
Unreliable Networks
- The internet and most internal networks in datacenters (often Ethernet) are asynchronous packet networks.
Example of The Problems That May Occur When Sending a Request
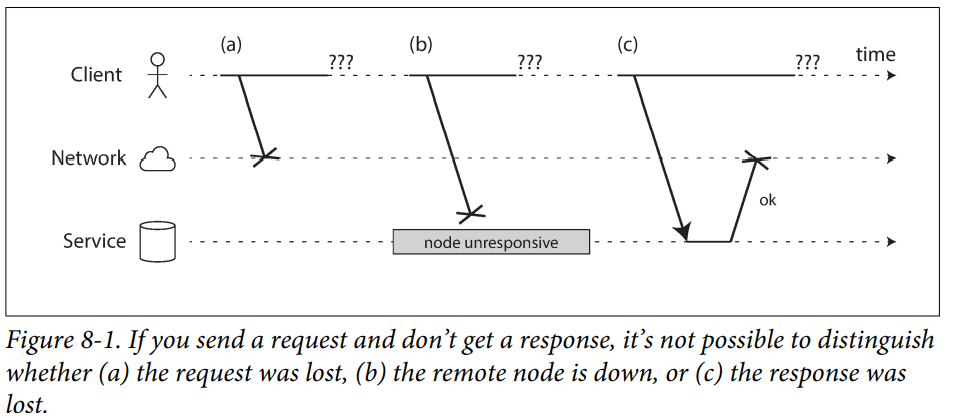
Network Faults in Practice
When one part of the network is cut off from the rest due to a network fault, that is sometimes called a network partition or netsplit.
If the software is put in an unanticipated situation, it may do arbi‐ trary unexpected things.
Handling network faults doesn’t necessarily mean tolerating them. A valid approach may be to simply show an error message to users while your network is experiencing problems.
Detecting Faults
A load balancer needs to stop sending requests to a node that is dead (i.e., take it out of rotation).
In a distributed database with single-leader replication, if the leader fails, one of the followers needs to be promoted to be the new leader.
Rapid feedback about a remote node being down is useful, but you can’t count on it.
Timeouts and Unbounded Delays
A long timeout means a long wait until a node is declared dead. A short timeout detects faults faster, but carries a higher risk of incorrectly declaring a node dead when in fact it has only suffered a temporary slowdown.
2d + rwould be a reasonable timeout to use wheredis the delivery time of the packet,ris the time in which a non-failure node handles a request.For failure detection, it’s not sufficient for the system to be fast most of the time: if your timeout is low, it only takes a transient spike in round-trip times to throw the system off-balance.
network congestion is when a busy network link, a packet may have to wait a while until it can get a slot.
TCP considers a packet to be lost if it is not acknowledged within some timeout.
UDP is a good choice in situations where delayed data is worthless. For example, in a VoIP phone call, there probably isn’t enough time to retransmit a lost packet before its data is due to be played over the loudspeakers.
Synchronous Versus Asynchronous Networks
The bounded delay is a term used to describe a network in which the total delay experienced by data traversing the network can be guaranteed not to exceed some predetermined value.
The circuit in a telephone network is very different from a TCP connection: a circuit is a fixed amount of reserved bandwidth which nobody else can use while the circuit is established, whereas the packets of a TCP connection opportunistically use whatever network bandwidth is available.
Data centre networks and the internet use packet switching as they are optimized for bursty traffic.
The internet shares network bandwidth dynamically.
Latency guarantees are achievable in certain environments, if resources are statically partitioned.
Multi-tenancy with dynamic resource partitioning provides better utilization, so it is cheaper, but it has the downside of variable delays.
Unreliable Clocks
Measure duration is the time interval between a request being sent and a response is received, whereas describe points in time are events that occur on a particular date, at a particular time.
Each machine on the network has its own clock, which is an actual hardware device usually a quartz crystal oscillator. These devices are not perfectly accurate, so each machine has its own notion of time, which may be slightly faster or slower than on other machines.
Monotonic Versus Time-of-Day Clocks
Modern computers have at least two different kinds of clocks: a time-of-day clock and a monotonic clock.
A time-of-day clock does what you intuitively expect of a clock: it returns the current date and time according to some calendar (also known as wall-clock time) since the epoch: midnight UTC on January 1, 1970, according to the Gregorian calendar.
Time-of-day clocks are usually synchronized with NTP
A monotonic clock is suitable for measuring a duration (time interval), such as a timeout or a service’s response time.
On a server with multiple CPU sockets, there may be a separate timer per CPU, which is not necessarily synchronized with other CPUs.
In a distributed system, using a monotonic clock for measuring elapsed time is usually fine, because it doesn’t assume any synchronization between
ddifferent nodes’ clocks and is not sensitive to slight inaccuracies of measurement.
Clock Synchronization and Accuracy
- The quartz clock in a computer is not very accurate.
If a computer’s clock differs too much from an NTP server, it may refuse to synchronize.
NTP synchronization can only be as good as the network delay.
In virtual machines, the hardware clock is virtualized, which raises additional challenges for applications that need accurate timekeeping.
Relying on Synchronized Clocks
The problem with clocks is that while they seem simple and easy to use, they have a surprising number of pitfalls.
If its quartz clock is defective or its NTP client is misconfigured, most things will seem to work fine, even though its clock gradually drifts further and further away from reality.
If you use software that requires synchronized clocks, it is essential that you also carefully monitor the clock offsets between all the machines.
It is possible for two nodes to independently generate writes with the same timestamp, especially when the clock only has a millisecond resolution.
The most common implementation of snapshot isolation requires a monotonically increasing transaction ID. If a write happened later than the snapshot (i.e., the write has a greater transaction ID than the snapshot), that write is invisible to the snapshot transaction. On a single-node database, a simple counter is sufficient for generating transaction IDs.
A great idea is that if you have two confidence intervals, each consisting of the earliest and latest possible timestamp (A = [A earliest, A latest] and B = [B earliest, B latest]), and those two intervals do not overlap (i.e., A earliest < A latest < B earliest < B latest), then B definitely happened after A—there can be no doubt. Only if the intervals overlap are we unsure in which order A and B happened.
Process Pauses
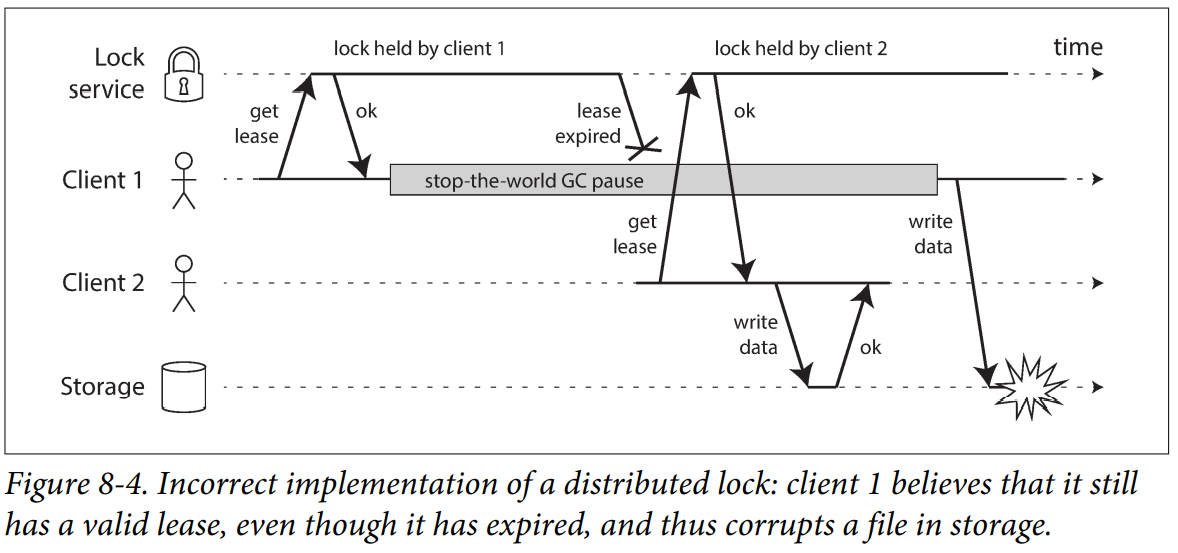
Only one node can hold the lease at any one time—thus, when a node obtains a lease, it knows that it is the leader for some amount of time, until the lease expires. In order to remain leader, the node must periodically renew the lease before it expires. If the node fails, it stops renewing the lease, so another node can take over when it expires.
Many programming language runtimes (such as the Java Virtual Machine) have a garbage collector (GC) that occasionally needs to stop all running threads. These “stop-the-world” GC pauses have sometimes been known to last for several minutes.
In embedded systems, real-time means that a system is carefully designed and tested to meet specified timing guarantees in all circumstances. This meaning is in contrast to the more vague use of the term real-time on the web, where it describes servers pushing data to clients and stream processing without hard response time constraints.
Providing real-time guarantees in a system requires support from all levels of the software stack.
For most server-side data processing systems, real-time guarantees are simply not economical or appropriate.
We can use the garbage collector only for short-lived objects and to restart processes periodically before they accumulate enough long-lived objects to require a full GC of long-lived objects. One node can be restarted at a time, and traffic can be shifted away from the node before the planned restart, like in a rolling upgrade. It cannot fully prevent garbage collection pauses, but it can usefully reduce their impact on the application.
Knowledge, Truth, and Lies
- Although it is possible to make software well-behaved in an unreliable system model, it is not straightforward to do so.
The Truth is Defined by The Majority
- A node cannot necessarily trust its own judgment of a situation. A distributed system cannot exclusively rely on a single node, because a node may fail at any time, potentially leaving the system stuck and unable to recover. Instead, many distributed algorithms rely on a quorum, that is, voting among the nodes, so decisions require some minimum number of votes from several nodes in order to reduce the dependence on any one particular node.
- It is a good idea for any service to protect itself from accidentally abusive clients.
Byzantine Faults
- If a node may claim to have received a particular message when in fact it didn’t. Such behaviour is known as a Byzantine fault.
Peer-to-peer networks like Bitcoin and other blockchains can be considered to be a way of getting mutually untrusting parties to agree on whether a transaction happened or not, without relying on a central authority.
Web applications do need to expect arbitrary and malicious behaviour of clients that are under end-user control, such as web browsers.
A bug in the software could be regarded as a Byzantine fault, but if you deploy the same software to all nodes, then a Byzantine fault-tolerant algorithm cannot save you.
System Model and Reality
- Algorithms need to be written in a way that does not depend too heavily on the details of the hardware and software configuration on which they are run.
Three System Models are in Common Use Regarding to Timing Assumptions
Synchronous model The synchronous model assumes bounded network delay, bounded process pauses, and bounded clock error.
Partially synchronous model Partial synchrony means that a system behaves like a synchronous system most of the time, but it sometimes exceeds the bounds for network delay, process pauses, and clock drift.
Asynchronous model In this model, an algorithm is not allowed to make any timing assumptions, and it does not even have a clock.
Most Common System Models for Nodes
- Crash-stop faults
- Crash-recovery faults
Byzantine (arbitrary) faults
Safety is often informally defined as nothing bad happens, and liveness as something good eventually happens.
- In liveness property it may not hold at some point in time, but there is always hope that it may be satisfied in the future.
- Fault tolerance and low latency (by placing data geographically close to users) are equally important goals, and those things can't be achieved with a single node.
Thank you, and goodbye!




