Designing Data Intensive Applications - Chapter 9
Book Summary

Consistency Guarantees
- Most replicated databases provide at least eventual consistency, which means that if you stop writing to the database and wait for some unspecified length of time, then eventually all read requests will return the same value.
Eventual consistency is hard for application developers because it is so different from the behaviour of variables in a normal single-threaded program. If you assign a value to a variable and then read it shortly afterwards, you don’t expect to read back the old value, or for the read to fail.
Transaction isolation is primarily about avoiding race conditions due to concurrently executing transactions, whereas distributed consistency is mostly about coordinating the state of replicas in the face of delays and faults.
Linearizability
- The basic idea of linearizability is to make a system appear as if there were only one copy of the data, and all operations on it are atomic. It is a recency guarantee.
What Makes a System Linearizable?
- An example of a linearizable system, In a linearizable system we imagine that there must be some point in time (between the start and end of the write operation) at which the value of x atomically flips from 0 to 1. Thus, if one client’s read returns the new value 1, all subsequent reads must also return the new value, even if the write operation has not yet been completed.
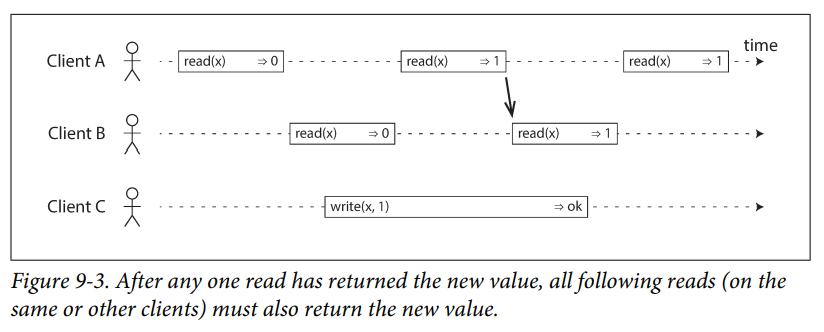
It is possible (though computationally expensive) to test whether a system’s behaviour is linearizable by recording the timings of all requests and responses, and checking whether they can be arranged into a valid sequential order.
Serializability is an isolation property of transactions, where every transaction may read and write multiple objects (rows, documents, records). It guarantees that transactions behave the same as if they had been executed in some serial order.
- A database may provide both serializability and linearizability, and this combination is known as strict serializability or strong one-copy serializability.
Relying on Linearizability
A system that uses single-leader replication needs to ensure that there is indeed only one leader, not several (split brain). One way of electing a leader is to use a "lock".
Uniqueness constraints are common in databases.
In real applications, it is sometimes acceptable to treat such constraints loosely (for example, if a flight is overbooked, you can move customers to a different flight and offer them compensation for the inconvenience). In such cases, linearizability may not be needed.
Linearizability is not the only way of avoiding this race condition, but it’s the simplest to understand.
Implementing Linearizable Systems
The most common approach to making a system fault-tolerant is to use replication.
In a system with single-leader replication, the leader has the primary copy of the data that is used for writes, and the followers maintain backup copies of the data on other nodes.
Consensus protocols contain measures to prevent split brain and stale replicas. consensus algorithms can implement linearizable storage safely. This is how ZooKeeper and etcd work.
Systems with multi-leader replication are generally not linearizable, because they concurrently process writes on multiple nodes and asynchronously replicate them to other nodes.
Cassandra waits for read repair to complete on quorum reads, but it loses linearizability if there are multiple concurrent writes to the same key, due to its use of
last-write-winsconflict resolution.
The Cost of Linearizability
If your application requires linearizability, and some replicas are disconnected from the other replicas due to a network problem, then some replicas cannot process requests while they are disconnected: they must either wait until the network problem is fixed or return an error (either way, they become unavailable).
If your application does not require linearizability, then it can be written in a way that each replica can process requests independently, even if it is disconnected from other replicas (e.g., multi-leader). In this case, the application can remain available in the face of a network problem, but its behaviour is not linearizable.
CAP is sometimes presented as Consistency, Availability, Partition tolerance: pick 2 out of 3. Unfortunately, putting it this way is misleading because network partitions are a kind of fault, so they aren’t something about which you have a choice: they will happen whether you like it or not.
- In a network with highly variable delays, the response time of linearizable reads and writes is inevitably going to be high.
Ordering Guarantees
Ordering and Causality
If a question is answered, then clearly the question had to be there first, because the person giving the answer must have seen the question. We say that there is a causal dependency between the question and the answer.
If a system obeys the ordering imposed by causality, we say that it is causally consistent.
A total order allows any two elements to be compared, so if you have two elements, you can always say which one is greater and which one is smaller.
Linearizability implies causality: any system that is linearizable will preserve causality correctly.
Making a system linearizable can harm its performance and availability, especially if the system has significant network delays.
In order to determine causal dependencies, we need some way of describing the “knowledge” of a node in the system.
In order to determine the causal ordering, the database needs to know which version of the data was read by the application.
Sequence Number Ordering
we can create sequence numbers in a total order that is consistent with causality: vii we promise that if operation A causally happened before B, then A occurs before B in the total order (A has a lower sequence number than B). Concurrent operations may be ordered arbitrarily.
There is actually a simple method for generating sequence numbers that is consistent with causality. It is called a "Lamport timestamp".
Lamport timestamp : Each node has a unique identifier, and each node keeps a counter of the number of operations it has pro‐ cessed. The Lamport timestamp is then simply a pair of (counter, node ID). Two nodes may sometimes have the same counter value, but by including the node ID in the timestamp, each timestamp is made unique.
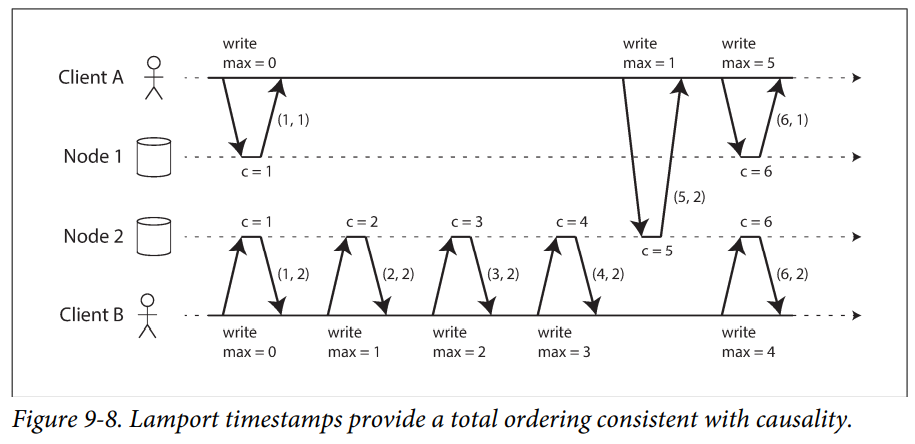
Lamport timestamps are sometimes confused with version vectors. Although there are some similarities, they have a different purpose: version vectors can distinguish whether two operations are concurrent or whether one is causally dependent on the other, whereas Lamport timestamps always enforce a total ordering.
In order to implement something like a uniqueness constraint for user names, it’s not sufficient to have a total ordering of operations, you also need to know when that order is finalized. If you have an operation to create a username, and you are sure that no other node can insert a claim for the same username ahead of your operation in the total order, then you can safely declare the operation successful.
Total Order Broadcast
- Total order broadcast is usually described as a protocol for exchanging messages between nodes. It requires that two safety properties always be satisfied:
- Reliable delivery :
No messages are lost: if a message is delivered to one node, it is delivered to all nodes. Totally ordered delivery :
Messages are delivered to every node in the same order.A correct algorithm for total order broadcast must ensure that the reliability and ordering properties are always satisfied, even if a node or the network is faulty.
Consensus services such as ZooKeeper and etcd implement total order broadcast.
Total order broadcast can be used to implement serializable transactions: if every message represents a deterministic transaction to be executed as a stored procedure, and if every node pro‐ cesses those messages in the same order, then the partitions and replicas of the database are kept consistent with each other.
Total order broadcast is also useful for implementing a lock service that provides fencing tokens.
Total order broadcast is asynchronous: messages are guaranteed to be delivered reliably in a fixed order, but there is no guarantee about when a message will be delivered.
If you have total order broadcast, you can build linearizable storage on top of it.
In general, if you think hard enough about linearizable sequence number generators, you inevitably end up with a consensus algorithm.
Distributed Transactions and Consensus
Informally, the goal is simply to get several nodes to agree on something.
"two-phase commit" (2PC) algorithm is the most common way of solving atomic commit and is implemented in various databases, messaging systems, and application servers.
2PC is a kind of consensus algorithm, but not a very good one.
Atomic Commit and Two-Phase Commit (2PC)
Atomicity prevents failed transactions from littering the database with half-finished results and half-updated states. This is especially important for multi-object transactions.
Atomicity ensures that the secondary index stays consistent with the primary data (if the index became inconsistent with the primary data, it would not be very useful).
For transactions that execute at a single database node, atomicity is commonly implemented by the storage engine.
A transaction commit must be irrevocable, you are not allowed to change your mind and retroactively abort a transaction after it has been committed.
2PC is used internally in some databases and also made available to applications in the form of XA transactions.
"2PC" provides atomic commit in a distributed database, whereas "2PL" provides serializable isolation.
This process is somewhat like the traditional marriage ceremony in Western cultures: the minister asks the bride and groom individually whether each wants to marry the other, and typically receives the answer “I do” from both. After receiving both acknowledgements, the minister pronounces the couple husband and wife: the transaction is committed, and the happy fact is broadcast to all attendees. If either bride or groom does not say “yes,” the ceremony is aborted.
- As an alternative to 2PC, an algorithm called three-phase commit (3PC) has been proposed. However, 3PC assumes a network with bounded delay and nodes with bounded response times; in most practical systems with unbounded network delay and process pauses, it cannot guarantee atomicity.
Distributed Transactions in Practice
Database-internal transactions do not have to be compatible with any other system, so they can use any protocol and apply optimizations specific to that particular technology
Heterogeneous distributed transactions allow diverse systems to be integrated in powerful ways.
Database transactions usually take a row-level exclusive lock on any rows they modify, to prevent dirty writes.
If you want serializable isolation, a database using two-phase locking would also have to take a shared lock on any rows read by the transaction.
When using two-phase commit, a transaction must hold onto the locks throughout the time it is in doubt.
XA transactions solve the real and important problem of keeping several participant data systems consistent with each other.
Distributed transactions have a tendency of amplifying failures, which runs counter to our goal of building fault-tolerant systems.
Fault-Tolerant Consensus
Consensus algorithm must satisfy the following properties :
Uniform agreement : No two nodes decide differently.
Integrity : No node decides twice.
Validity : If a node decides value v, then v was proposed by some node.
Termination : Every node that does not crash eventually decides some value.
If you don’t care about fault tolerance, then satisfying the first three properties is easy: you can just hardcode one node to be the “dictator,” and let that node make all of the decisions.
The termination property formalizes the idea of fault tolerance.
Most implementations of consensus ensure that the safety properties : agreement, integrity, and validity are always met, even if a majority of nodes fail or there is a severe network problem.
The best-known fault-tolerant consensus algorithms are Viewstamped Replication (VSR), Paxos, Raft, and Zab.
Some databases perform automatic leader election and failover, promoting a follower to be the new leader if the old leader fails.
Consensus systems always require a strict majority to operate. And consensus systems generally rely on timeouts to detect failed nodes.
Most consensus algorithms assume a fixed set of nodes that participate in voting, which means that you can’t just add or remove nodes in the cluster. Dynamic membership extensions to consensus algorithms allow the set of nodes in the cluster to change over time, but they are much less well understood than static membership algorithms.
Sometimes, consensus algorithms are particularly sensitive to network problems.
Membership and Coordination Services
- ZooKeeper and etcd are designed to hold small amounts of data that can fit entirely in memory (although they still write to disk for durability), so you wouldn’t want to store all of your application’s data here.
One example in which the ZooKeeper/Chubby model works well is if you have several instances of a process or service, and one of them needs to be chosen as leader or primary.
"ZooKeeper", "etcd", and "Consul" are also often used for service discovery that is, to find out which IP address you need to connect to in order to reach a particular service. In cloud data center environments, where it is common for virtual machines to continually come and go, you often don’t know the IP addresses of your services ahead of time. Instead, you can configure your services such that when they start up they register their network endpoints in a service registry, where they can then be found by other services.
Not every system necessarily requires consensus: for example, leaderless and multi-leader replication systems typically do not use global consensus.
Thank you, and goodbye!




