Distributed Systems: Consistency & Replication
Distributed Systems Serie

Introduction
Reasons for replication
To keep replicas consistent, we generally need to ensure that all conflicting operations are done in the same order everywhere.
Conflicting operations:
Read–write conflict: a read operation and a write operation act concurrently.
Write–write conflict: two concurrent write operations.
Guaranteeing global ordering on conflicting operations may be a costly operation, downgrading scalability. Solution: weaken consistency requirements so that hopefully global synchronization can be avoided.
Replication as a scaling technique
Consistency is achieved by ensuring that the copies of data are always the same, ensuring that read operations performed at any copy will always return the same result. However, maintaining consistency can be challenging due to the need for global synchronization, which is inherently costly in terms of performance.
Replication and caching can be applied as scaling techniques, leading to improved performance. However, keeping all copies consistent generally requires global synchronization, which is inherently costly in terms of performance.
Data-centric consistency models
It is a contract between a (distributed) data store and processes, in which the data store specifies precisely what the results of read and write operations are in the presence of concurrency.

Continuous consistency
There is no such thing as a best solution to replicating data. Replicating data poses consistency problems that cannot be solved efficiently in a general way. Only if we loosen consistency can there be hope for attaining efficient solutions. Unfortunately, there are also no general rules for loosening consistency: exactly what can be tolerated is highly dependent on applications.
Numerical deviation can also be understood in terms of the number of updates that have been applied to a given replica, but have not yet been seen by others.
Staleness deviations relate to the last time a replica was updated. For some applications, it can be tolerated that a replica provides old data as long as it is not too old.
Consistent ordering of operations
Sequential consistency
In which the result of any execution is the same as if the operations of all processes were executed in some sequential order, and the operations of each individual process appear in this sequence in the order specified by its program.

where :
W(x)a : write in the variable "x" the value "a".
R(x)b : the result of reading the variable "x" is the value "b".
Causal consistency
In which writes that are potentially causally related must be seen by all processes in the same order. Concurrent writes may be seen in a different order by different processes.
Note: This sequence is allowed with a causally-consistent store, but not with a sequentially consistent store.

Grouping operations
The basic idea is that you don’t care that reads and writes of a series of operations are immediately known to other processes. You just want the effect of the series itself to be known.
No data access is allowed to be performed until all previous accesses to locks have been performed.
No access to a lock is allowed to be performed until all previous writes have been completed everywhere.
Consistency versus coherence
Consistency model: describes what can be expected with respect to a set of data items.
Coherence models: describe what can be expected to hold for only a single data item.
Eventual consistency
The basic idea is that if no updates take place for a long time, all replicas will gradually become consistent, that is, have exactly the same data stored. As in many database systems, most processes hardly ever perform update operations; they mostly read data from the database. Only one, or very few processes perform update operations.
Client-centric consistency models
Data-centric consistency models aim at providing a systemwide consistent view on a data store. An important assumption is that concurrent processes may be simultaneously updating the data store, and that it is necessary to provide consistency in the face of such concurrency
Notations
W1(x2) → is the write operation by process P1 that leads to version x2 of x.
W1(xi ; xj) → indicates P1 produces version xj based on a previous version xi .
W1(xi | xj) → indicates P1 produces version xj concurrently to version xi .
Monotonic reads
In which if a process reads the value of a data item x, any successive read operation on x by that process will always return that same or a more recent value.
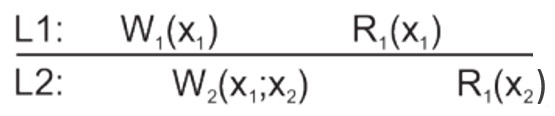
Monotonic writes
In which a write operation by a process on a data item x is completed before any successive write operation on x by the same process.

Read your writes
In which the effect of a write operation by a process on data item x, will always be seen by a successive read operation on x by the same process.
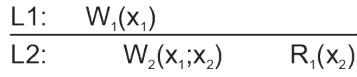
Writes follow reads
In which a write operation by a process on a data item x following a previous read operation on x by the same process, is guaranteed to take place on the same or a more recent value of x that was read.
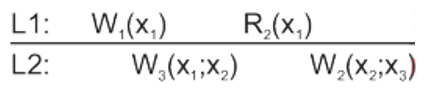
Replica management
The placement problem itself is split into two subproblems: that of placing replica servers, and that of placing content.
The difference is a subtle one and the two issues are often not clearly separated.
Replica-server placement → is concerned with finding the best locations to place a server that can host (part of) a data store.
Content placement → deals with finding the best servers for placing content.
Content replication and placement
When it comes to content replication and placement, three different types of replicas can be distinguished logically organized as shown:

Content distribution
Pull versus push protocols
In a push-based approach, updates are propagated to other replicas without those replicas even asking for the updates.
in a pull-based approach, a server or client requests another server to send it any updates it has at that moment.
| Issue | Push-based | Pull-based |
| State at server | List of client replicas and caches | None |
| Messages sent | Update (and possibly fetch update later) | Poll and update |
| Response time at client | Immediate (or fetch-update time) | Fetch-update time |
Consistency protocols
Primary-based protocols
Primary-based protocols are distributed protocols that designate one node(the primary node) as the central point of control for coordinating the operations in the system. The primary node is responsible for managing the order in which operations are executed and ensuring sequential consistency. All operations initially go through the primary node.

Replicated-write protocols
In which write operations can be carried out at multiple replicas instead of only one, as in the case of primary-based replicas.
Quorum-based protocols
Ensure that each operation is carried out in such a way that a majority vote is established: distinguish read quorum and write quorum.
Nr +Nw > N
Nw > N/2
where :
Nr → is the number of reading approvals.
Nw → is the number of writing approvals.
N → is the total number of replicas.
Thank you, and goodbye!



