


Introduction to fault tolerance
Basic concepts
A component provides services to clients. To provide services, the component may require the services from other components. A component may depend on some other component.
Requirements related to dependability
| Requirement | Description |
| Availability | Probability that the system is operating correctly at any instant. |
| Reliability | Focus on period of time not just instant as the availability. It is the property that the system can run continuously without failure. |
| Safety | Very low probability of catastrophes. When the system temporarily fails. |
| Maintainability | How easy can a failed system be repaired. |
Mean Time To Failure (MTTF): The average time until a component fails.
Mean Time To Repair (MTTR): The average time needed to repair a component.
Mean Time Between Failures (MTBF): Simply MTTF + MTTR.
Failure, error, fault
| Term | Description | Example |
| Failure | A component is not living up to its specifications. | Crashed program |
| Error | Part of a component that can lead to a failure. | Programming bug |
| Fault | Cause of an error. | Sloppy programmer |
Transient faults: occur once and then disappear.
Intermittent fault: occurs, then vanishes of its own accord, then reappears, and so on.
Permanent fault: is one that continues to exist until the faulty component is replaced.
Failure models
Types of failures
| Type | Description of the server's behavior |
| Crash failure | Halts, but is working correctly until it halts |
| Omission failure | Fails to respond to incoming requests. Receive omission: Fails to receive incoming messages. Send omission: Fails to send messages. |
| Timing failure | Response lies outside a specified time interval. |
| Response failure | Response is incorrect. Value failure: The value of the response is wrong. State-transition failure: Deviates from the correct flow of control. |
| Arbitrary failure | May produce arbitrary responses at arbitrary times. |
Asynchronous system: no assumptions about process execution speeds or message delivery times → cannot reliably detect crash failures.
Synchronous system: process execution speeds and message delivery times are bounded → we can reliably detect omission and timing failures.
Failure masking by redundancy
Types of redundancy
| Type | Description |
| Information redundancy | Add extra bits to data units so that errors can recovered when bits are garbled. |
| Time redundancy | Design a system such that an action can be performed again if anything went wrong. Typically used when faults are transient or intermittent. |
| Physical redundancy | add equipment or processes in order to allow one or more components to fail. This type is extensively used in distributed systems. |
Process resilience
Resilience by process groups
The basic idea is to protect against malfunctioning processes through process replication, organizing multiple processes into process groups.
Flat group
All processes are equal.
No single point of failure.
Resembles active replication where the operation is sent to all servers to be executed by all of them.

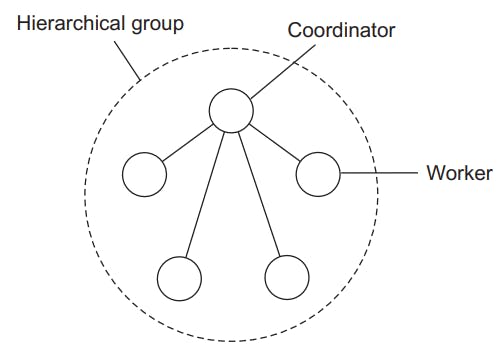
Hierarchical group
The coordinator is a single point of failure, if it is down, the whole group is down. Hence they need to elect a leader.
Decision making is easy, the coordinator makes decisions, unlike flat group where all processes are equal.
Failure masking and replication
How large does a k-fault tolerant group need to be?
With halting failures (crash/omission/timing failures): we need a total of k +1 members as no member will produce an incorrect result, so the result of one member is good enough.
With arbitrary failures: we need 2k +1 members so that the correct result can be obtained through a majority vote.
Paxos
Paxos is an algorithm that enables a distributed set of computers to achieve consensus over an asynchronous network. It works by allowing a group of nodes to agree on a single value, even if some nodes fail or are unresponsive.
In Paxos, a server S cannot execute an operation o until it has received a LEARN(o) from all other nonfaulty servers.
Paxos needs at least three servers.
In Paxos with three servers, a server S cannot execute an operation o until it has received at least one (other) LEARN(o) message, so that it knows that a majority of servers will execute o.
Consensus in faulty systems with arbitrary failures
We consider process groups in which communication between process is inconsistent:
Improper forwarding of messages.
Or telling different things to different processes.
The Byzantine algorithm
It is a fault-tolerance algorithm that ensures that all nodes (3k+1 nodes) in a distributed system can reach a consensus despite arbitrary faults or malicious nodes. It uses a voting system to determine the final agreed-upon value and requires a certain number of nodes to agree to reach a consensus. The quorum size is typically set to be a majority of nodes. While this approach can handle faults and malicious attacks.
Failure detection
Practical failure detection
If P didn't receive a heartbeat from Q within time t: P suspects Q.
If Q later sends a message (which is received by P):
P stops suspecting Q.
P increases the timeout value t.
Note: if Q did crash, P will keep suspecting Q.
Distributed commit
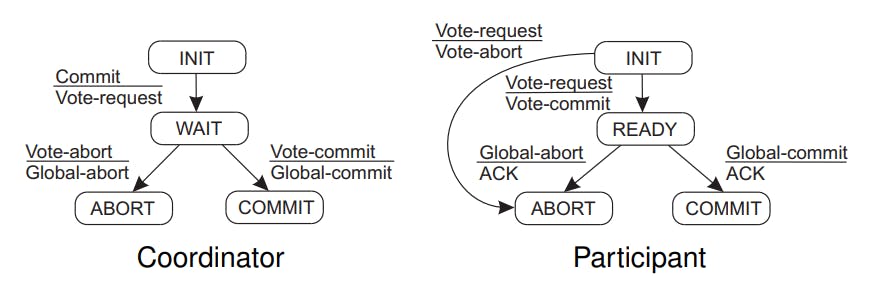
The Two-phase commit protocol (2PC)
It is an algorithm used for coordinating distributed transactions. The algorithm ensures that all participants in a transaction agree to either commit or abort the transaction.
There are two phases of 2PC: the prepare phase and the commit phase.
During the prepare phase, the coordinator sends a PREPARE message to the participants to verify that they are ready to commit. If all participants are ready, the coordinator sends a COMMIT message. If any participant is not ready, the coordinator sends an ABORT message.
During the commit phase, participants execute the transaction and send an ACK message to the coordinator. Once the coordinator receives the ACK message from all participants, it sends a COMMIT message to finalize the transaction. If any participant fails to respond, the transaction is aborted.
Recovery
When a failure occurs, we need to bring the system into an error-free state:
Forward error recovery: This finds a new state from which the system can continue operation.
Backward error recovery: This brings the system back into a previous error-free state.
We have two approaches for recovery:
Each process takes a checkpoint after a globally coordinated action.
Instead of taking an (expensive) checkpoint, try to replay your (communication) behavior from the most recent checkpoint ⇒ store messages in a log.
I will leave the last chapter (chapter 9) for you to read from the book, to encourage you to read the great book from which this series is based.
Thank you, and goodbye!