Distributed Systems: Naming
Distributed Systems Serie

Names, identifiers, and addresses
Names are used to denote entities in a distributed system. To operate on an entity, we need to access it at an access point. Access points are entities that are named by means of an address.
A name that has no meaning at all; it is just a random string. Pure names can be used for comparison only. an identifier is a name having some specific properties, and it refers to at most one entity.
To operate on an entity, it is necessary to access it, for which we need an access point. An access point is yet another, but special, kind of entity in a distributed system. The name of an access point is called an address.
Flat naming
Simple solutions
We have two simple solutions for locating an entity: broadcasting and forwarding pointers. Both solutions are mainly applicable only to local-area networks. Nevertheless, in that environment, they often do the job well, making their simplicity particularly attractive. However, the use of broadcasting and forwarding pointers imposes scalability problems. Broadcasting or multi-casting is difficult to implement efficiently in large-scale networks whereas long chains of forwarding pointers introduce performance problems and are susceptible to broken links.
Broadcasting
Simply broadcast the ID, requesting the entity to return its current address.
Forwarding pointers
Each time an entity moves, it leaves behind a pointer telling where it has gone to.
Home-based approaches
The goal of mobile IP is to maintain the TCP connection between a mobile host and a static host while reducing the effects of location changes while the mobile host is moving around, without having to change the underlying TCP/IP. To solve the problem, the RFC allows for a kind of proxy agent to act as a middle-man between a mobile host and a correspondent host.

Distributed hash tables
A Distributed Hash Table is a decentralized data store that looks up data based on key-value pairs. Every node in a distributed hash table is responsible for a set of keys and their associated values. The key is a unique identifier for its associated data value, created by running the value through a hashing function. The data values can be any form of data.
Distributed hash tables are decentralized, so all nodes form the collective system without any centralized coordination.
Hierarchical approaches
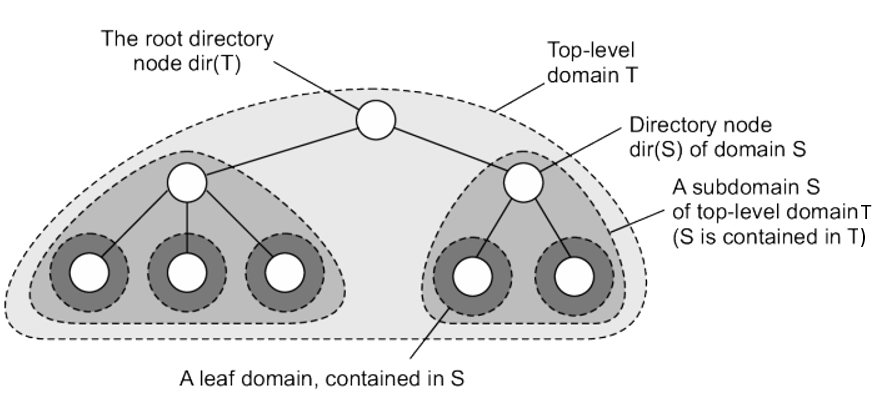
The basic idea is to build a large-scale search tree for which the underlying network is divided into hierarchical domains. Each domain is represented by a separate directory node.
Structured naming
Flat names are good for machines, but are generally not very convenient for humans to use. As an alternative, naming systems generally support structured names that are composed from simple, human-readable names. Not only file naming, but also host naming on the Internet follows this approach.
Name-spaces
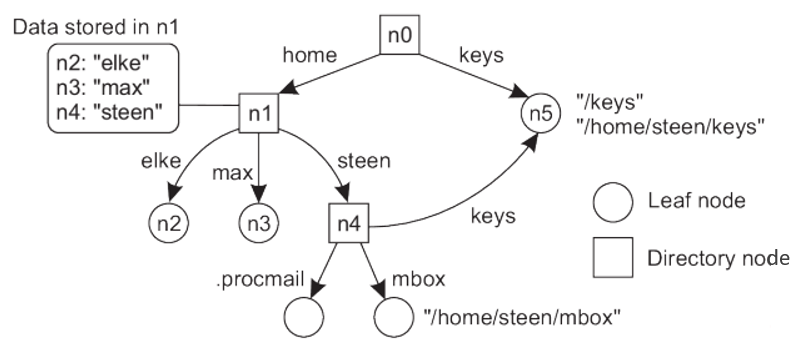
Names are commonly organized into what is called a name-space. Name-spaces for structured names can be represented as a labeled, directed graph with two types of nodes.
Leaf node represents a named entity and has the property that it has no outgoing edges. A leaf node generally stores information on the entity it is representing–for example, its address–so that a client can access it.
Directory node has a number of outgoing edges, each labeled with a name.
Name resolution
Name-spaces offer a convenient mechanism for storing and retrieving information about entities using names. More generally, given a path name, it should be possible to look up any information stored in the node referred to by that name. The process of looking up a name is called name resolution.
Comparison between name servers for implementing nodes in a name space
Item | Global | Administrational | Managerial |
Geographical scale | Worldwide | Organization | Department |
Number of nodes | Few | Many | Vast numbers |
Responsiveness | Seconds | Milliseconds | Immediate |
Update propagation | Lazy | Immediate | Immediate |
Number of replicas | Many | None or few | None |
Client-side caching | Yes | Yes | Sometimes |
Attribute-based naming
Directory services
In many cases, it is much more convenient to name, and look up entities by means of their attributes. The problem in lookup operations is that it can be extremely expensive, as they require to match requested attribute values, against actual attribute values.
Hierarchical implementations: LDAP
The essence of the solution of the previous section problem :
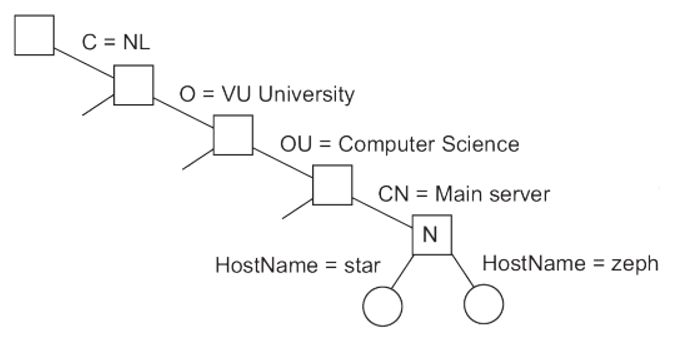
Directory Information Base: a collection of all directory entries in an LDAP service.
Each record is uniquely named as a sequence of naming attributes (called Relative Distinguished Name), so that it can be looked up.
Directory Information Tree: the naming graph of an LDAP directory service; each node represents a directory entry.
Thank you, and goodbye!



