
Chapter 1 - introduction to algorithms
What are Algorithms?
An algorithm is a set of instructions for accomplishing a task, so it is a more general term than a specific technical term.
Big O notation
Let's say we want to compare between two algorithms, or as we said before two approaches of thinking, in terms of efficiency let's say for speed as long as the two algorithms lead us to the same desired results, then how can we do so?
Here comes the role of the Big O notation!
Big O notation is a special notation that tells you how fast an algorithm is. It doesn’t tell you the speed in seconds, Instead, it let you compare the number of operations by telling you how fast the algorithm grows.
There are other notations (such as Big Omega notation) that we can use to compare algorithms but the Big O notation is the most popular one as it is based on the algorithm worst case, and this is very practical because if you could handle the worst case of an algorithm then it would be easy to handle any other cases for the same algorithm. There will be much more coming up to make things more clear!
Binary Search
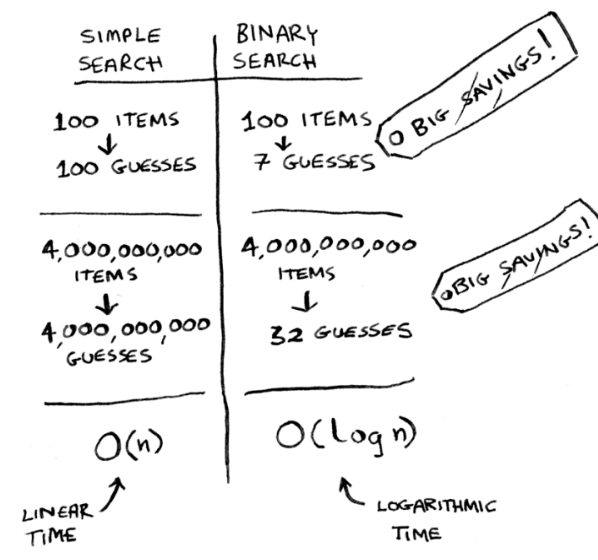
"Binary Search" is an algorithm to search in a sorted, indexed list of items in a hugely efficient way.
Suppose you’re searching for a person in the phone book. Their name starts with K. You could start at the beginning and keep flipping pages until you get to the Ks. But you’re more likely to start at a page in the middle because you know the Ks are going to be near the middle of the phone book.
This is a search problem. And all the similar cases that use the same algorithm to solve the problem use the "binary search" algorithm.
Algorithm Implementation
def binary_search(list, item):
low = 0
high = len(list)—1
while low <= high:
mid = (low + high)//2
guess = list[mid]
if guess == item:
return mid
if guess > item:
high = mid - 1
else:
low = mid + 1
return None
Algorithm Time Complexity
There is something else called space complexity will be mentioned later, but for this section, the time complexity is O(Log n)
How Did We Get the Time Complexity?
As in the binary search algorithm, we divide the list into two parts and search in one of them and by repeating this step we find the element we look for.
So the question is, how many times can you divide N by 2 until you have 1?
In a formula, it would be like this:
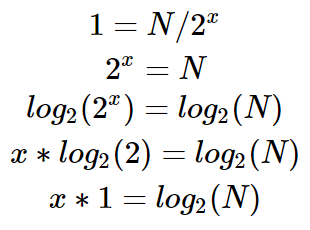
So the time complexity is O(Log n)
Chapter 2 - selection sort
How Memory Works
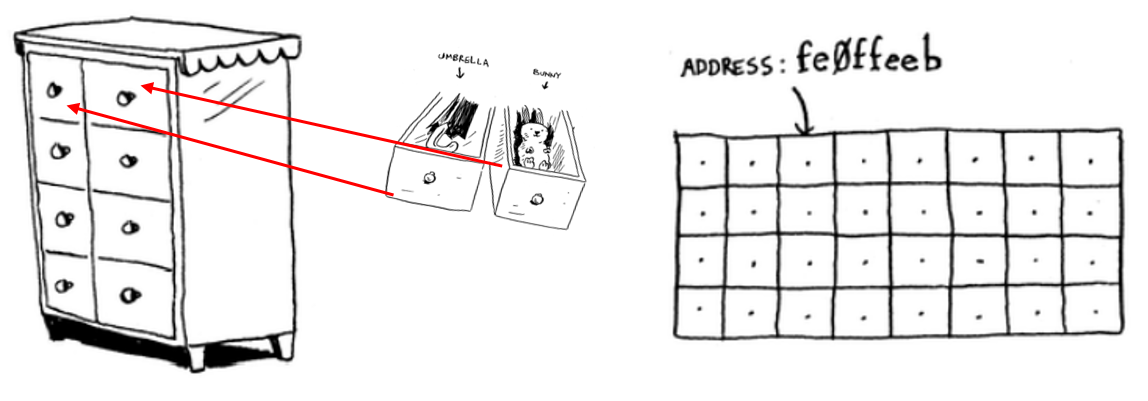
Computer memory is like a cupboard where you have several drawers. For each drawer, you can only store one element, and each drawer has a unique name (memory address) so you can call it after and in any conversation you can say in which drawer (memory position) you store your element.
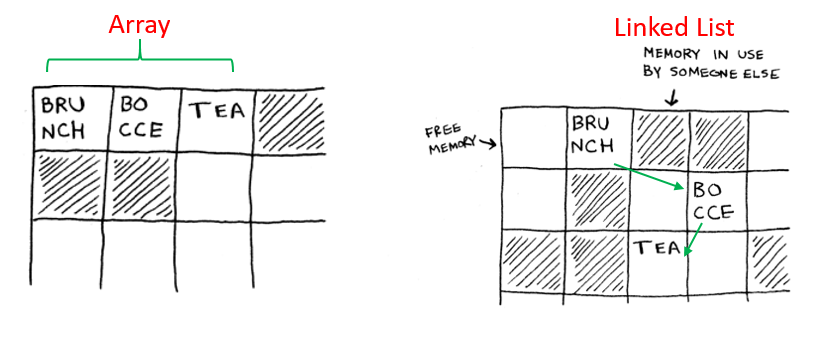
Arrays and Linked Lists
An array is a collection of similar data elements stored at contiguous memory locations.
A Linked List is a collection of data elements that don't have to be stored at contiguous memory locations.
It consists of nodes where each node is connected with the next node via a pointer.
Selection Sort
Selection sort works by taking the smallest element in an unsorted array and bringing it to the front. We will go through each item (from left to right) until we find the smallest one. The first item in the array is now sorted, while the rest of the array is unsorted so we repeat these steps on the unsorted part of the array until it is sorted.
Algorithm Implementation
def findSmallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
Algorithm Time Complexity
It is O(n^2) because we notice from the code above that we have 2 nested loops and the array size is "n", the worst case is n*n = n^2.
Oh no we said "worst case" 😯, so we are using the Big O notation 😉.
Chapter 3 - recursion
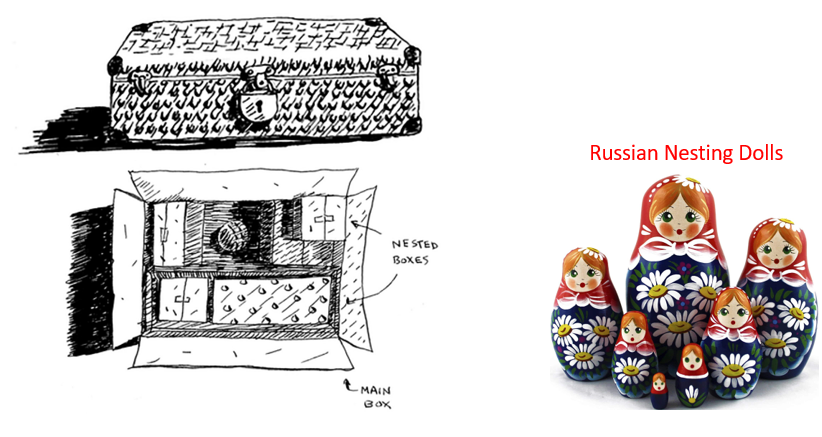
You may have seen one of those Russian nesting dolls games in which you have a small wooden doll which is put in a bigger one, which in turn is put in another bigger one, and so on. This is how recursion works and you can replace the dolls' example with anything else (for example boxes..)
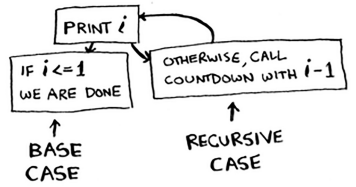
Base Case and Recursive Case
Base case: is the case in a recursive definition in which the solution is obtained directly.
Recursive case: is the case in a recursive definition in which the method is calling itself.
def countdown(i):
print(i)
if i <= 0: #Base case
return
else:
countdown(i-1)
So I hope you understand it now, So I hope you understand it now, So I hope you understand it now,...(where is the base case??!🤔)
Stacks
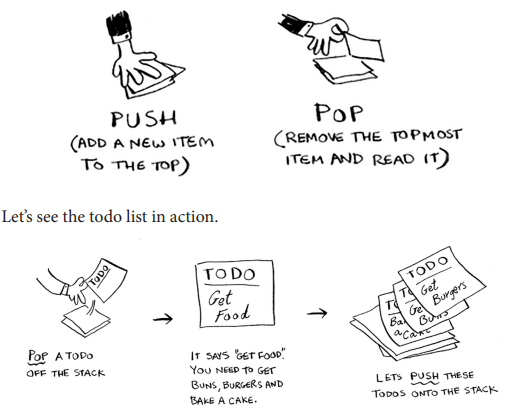
Stack is a data structure in which items are stored on top of each other. So the last element that gets into, is the first one to get out (called "LIFO").
It can be like a pile of papers with two operations "push", and "pop" as the image below shows.
Chapter 4 - quicksort
Divide and Conquer
To understand the Quicksort algorithm, you should at first understand the Divide and Conquer approach.
Divide and Conquer is a method to solve problems in which you divide the problem into several sub-problems, then you solve or conquer each one of them to solve the big problem.
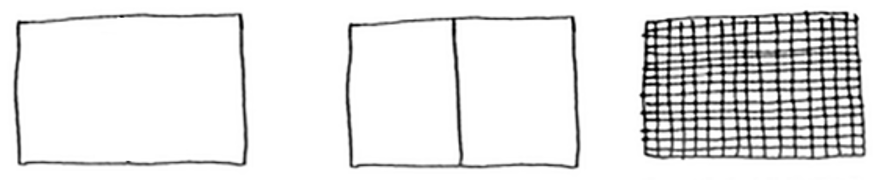
Quicksort
Quicksort is a sorting algorithm. It’s much faster than selection sort
and is frequently used in real life.
It works by breaking an array (partitioning it) into smaller ones and swapping (exchanging) the smaller ones, depending on a comparison with the 'pivot' element picked.
Algorithm Implementation
def quicksort(array):
if len(array) < 2:
return
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
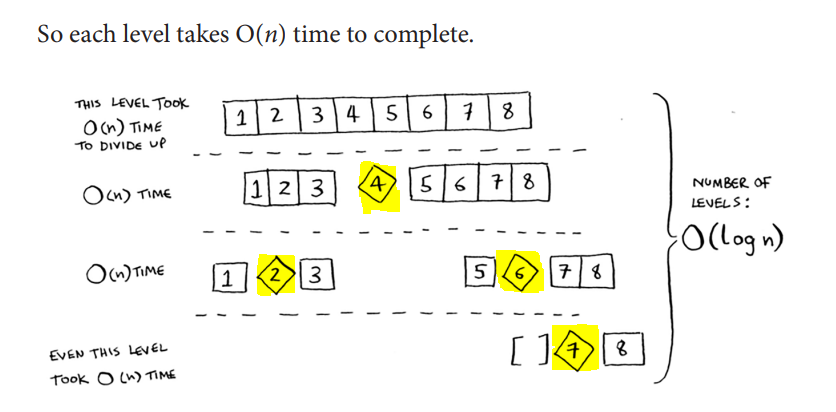
Algorithm Time Complexity
It is O(n Log n).
The reason is as each partitioning operation takes O(n) operations (one pass on the array). On average, each partitioning divides the array into two parts (which sums up to log(n) operations). In total, we have O(n * log n) operations.
Comparison Between Algorithms
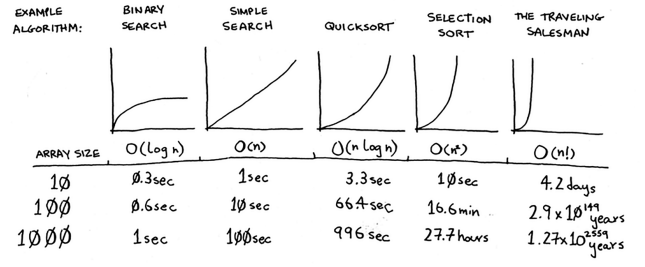
Chapter 5 - hash tables
Hash tables are (key, value) pairs-based tables where you search for the value using the key.
Imagine that you are in a grocery store, and when a customer buys a product, you have to look up the price in a book. You might say: "So I have to search for the item (key) then look at its price (value) and using the binary search algorithm then it would take O(log n)".
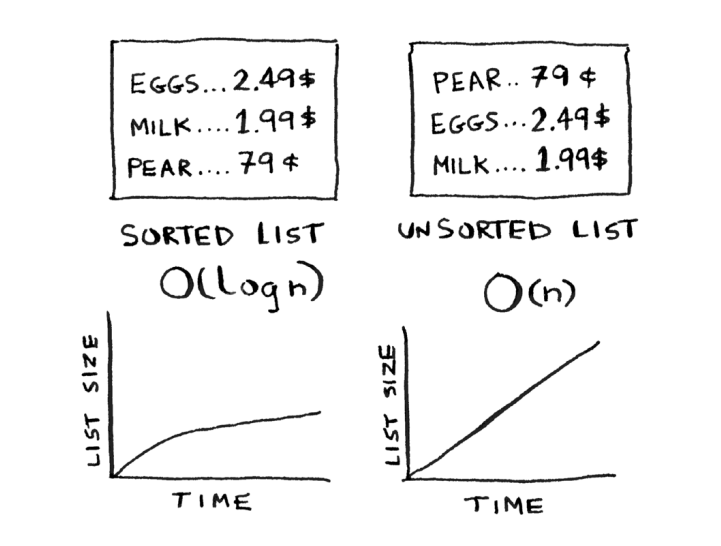
Now, what if I told you that we can get it in O(1) time complexity but with additional space (which is referred to as space complexity). This is when the hash tables role comes in.
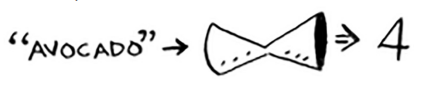
Hash Functions
Hashing functions are like magic black boxes where you insert something, and it gets out as another different mapped one.
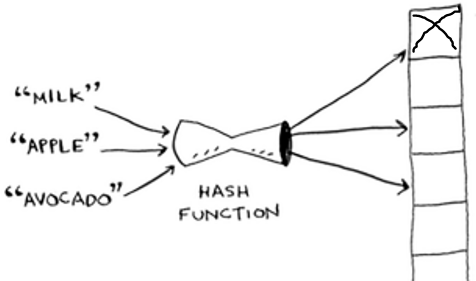
Collisions
When we use hash functions there is a possibility that the function maps two objects to the same spot in the array, So they will have the same position (index). Here a collision occurs.
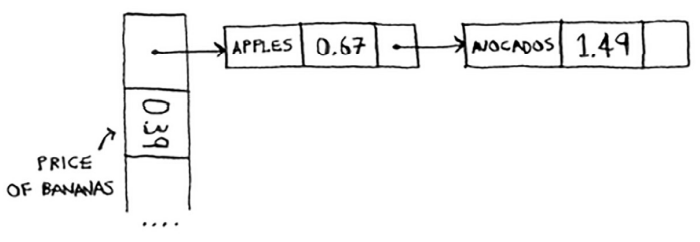
Solving Collision
There are many different ways to deal with collisions. The simplest one is this: if multiple keys map to the same slot, start a linked list at that slot.
Operations Time Complexity

Chapter 6 - breadth-first search
What is a graph?
Graph is a mathematical representation of a network and it describes the relationship between lines and points. A graph consists of some points and lines between them. The length of the lines and the position of the points do not matter. Each object in a graph is called a node.
Graphs are made up of nodes and edges. A node can be directly connected to many other nodes. Those nodes are called their neighbours.
Breadth-first search
Breadth-first search is a kind of search algorithm that runs on
graphs. It can help answer:
• Whether there is a path from node A to node B?
• What is the shortest path from node A to node B?
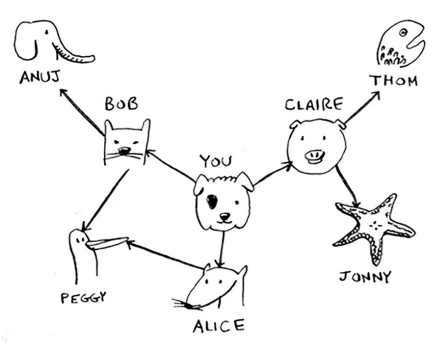
Implementing the Graph
We use dictionaries here to implement the graph.
So, for the previous graph, it is :
graph = {}
graph[“you”] = [“alice”, “bob”, “claire”]
graph[“bob”] = [“anuj”, “peggy”]
graph[“alice”] = [“peggy”]
graph[“claire”] = [“thom”, “jonny”]
graph[“anuj”] = []
graph[“peggy”] = []
graph[“thom”] = []
graph[“jonny”] = []
Implementing the Algorithm
The breadth-first search takes O(number of people + number of edges), and it’s more commonly written as O(V+E) (V for the number of vertices, E for the number of edges).
def search(name):
search_queue = deque()
search_queue += graph[name]
searched = []
while search_queue:
person = search_queue.popleft()
if not person in searched:
if person_is_seller(person):
print person + “ is a mango seller!”
return True
else:
search_queue += graph[person]
searched.append(person)
return False
Chapter 7 - Dijkstra’s algorithm
Dijkstra's algorithm allows us to find the shortest path between any two vertices of a graph for any weighted, directed graph with non-negative weights. It can handle graphs consisting of cycles, but negative weights will cause this algorithm to produce incorrect results.
Dijkstra's Algorithm Steps
- Find the “cheapest” node. This is the node you can get to in the least amount of time.
- Update the costs of the neighbours of this node.
- Repeat until you’ve done this for every node in the graph.
- Calculate the final path.
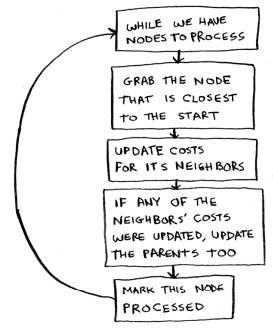
Implementation
def find_lowest_cost_node(costs):
lowest_cost = float(“inf”)
lowest_cost_node = None
for node in costs: Go through each node.
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost … set it as the new lowest-cost node.
lowest_cost_node = node
return lowest_cost_node
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
costs[n] = new_cost
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
Time complexity is O(V^2)(where V is the number of vertices in the graph)
Chapter 8 - greedy algorithms
Greedy Algorithm is an approach for solving a problem by selecting the best option available at the moment. It doesn't worry whether the current best result will bring the overall optimal result.
The Classroom Scheduling Problem
It is assigning a number of courses to classrooms taking into consideration constraints like classroom capacities and university regulations, and it is a famous example of greedy algorithms.
The Knapsack Problem
Given a set of items, each with a weight and a value, we have to determine the number of each item to include in a collection so that the total weight is less than or equal to a given limit and the total value is as large as possible.
We can solve it using the greedy algorithm except for the 0-1 Knapsack case.

NP-complete problems
An NP-complete problem is any of a class of computational problems for which no efficient solution algorithm has been found.
Traveling Salesperson Problem
The Problem Statement
Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?
It is an NP-complete problem.
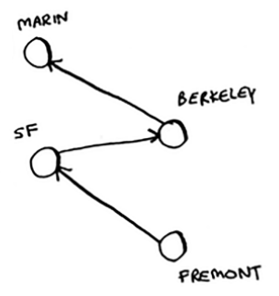
Chapter 9 - dynamic programming
The dynamic programming approach starts by solving subproblems and builds up to solving the big problem.
We can use it for the knapsack problem, we start by solving the problem for smaller knapsacks (or “sub-knapsacks”) and then work up to solve the original problem.
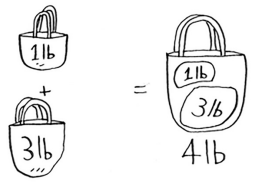
Chapter 10 - k-nearest neighbors
Introduction to Machine Learning
K-nearest neighbors or KNN is a really useful algorithm, and it’s your introduction to the magical world of machine learning!
• Classification = categorization into a group.
Machine learning is all about making your computer more intelligent.
• KNN is used for classification and regression and involves looking at the k-nearest neighbors.
• Regression = predicting a response (like a number)

Additional Resources (not included in the book)
Helpful problems to practice on LeetCode for the topics discussed :
Thank you and goodbye,




